Loading...
Loading...
Loading...
An ML pipeline is a structured workflow that automates various steps in machine learning, from data preprocessing to model deployment. It is crucial for:
# 1. General Questions on ML Pipelines ## Q1: What is an ML pipeline, and why is it important? An ML pipeline is a structured workflow that automates various steps in machine learning, from data preprocessing to model deployment. It is crucial for: ✅** ****Reproducibility** — Standardized steps ensure consistent results. ✅** ****Scalability** — Enables efficient handling of large datasets. ✅** ****Automation** — Reduces manual efforts in training and deployment. ✅** ****Monitoring & Maintenance** — Helps detect performance degradation and model drift. ## Q2: What are the key stages of an ML pipeline? A typical ML pipeline consists of the following stages: 1️⃣** ****Data Ingestion** — Collecting, cleaning, and transforming raw data. 2️⃣** ****Feature Engineering** — Selecting and creating meaningful features. 3️⃣** ****Model Training** — Experimenting with different models and hyperparameters. 4️⃣** ****Model Evaluation** — Comparing models using metrics like accuracy, F1-score, RMSE. 5️⃣** ****Model Versioning & Registry** — Storing trained models and their metadata. 6️⃣** ****Deployment** — Serving the model in a production environment. 7️⃣** ****Monitoring & Logging** — Tracking model performance and identifying drift. ## Q3: How does an ML pipeline improve model deployment? An ML pipeline enhances deployment by: ✔** ****Automating model selection** to reduce manual effort. ✔** ****Using model versioning** to ensure smooth rollbacks if needed. ✔** ****Integrating with CI/CD tools** for continuous training and deployment. ✔** ****Monitoring real-time performance** to track prediction accuracy and identify drift. # 2. Model Versioning and Registry ## Q4: What is model versioning, and why is it necessary? Model versioning keeps track of different iterations of a machine learning model, ensuring: ✅** ****Experiment tracking** — Allows comparisons between different models. ✅** ****Reproducibility** — Enables retraining with identical conditions. ✅** ****Rollback & Debugging** — Facilitates restoration of older models if the new one fails. ✅** ****Compliance & Auditability** — Maintains historical records for regulatory needs. ## Q5: How would you implement a model registry in an ML pipeline? A model registry can be implemented by: 1️⃣** ** **Storing models with metadata** , including training datasets and parameters. 2️⃣** ****Using a centralized repository** for versioned storage. 3️⃣** ****Automating model registration** within CI/CD pipelines. 4️⃣** ****Defining an approval workflow** to prevent unintended deployments. **Common tools for model versioning:** MLflow Model Registry, DVC, Kubeflow, AWS SageMaker Model Registry. # 3. Logging & Monitoring ## Q6: Why is logging important in an ML pipeline? Logging records events throughout the pipeline, ensuring: ✔** ****Debugging capability** — Helps trace errors in data preprocessing and training. ✔** ****Performance tracking** — Ensures models perform as expected over time. ✔** ****Compliance readiness** — Provides historical logs for audit purposes. ## Q7: What components should be logged in an ML pipeline? Important components to log include: ✅** ****Data Preprocessing** — Any transformations or handling of missing values. ✅** ****Model Training** — Hyperparameters, loss values, training duration. ✅** ****Model Inference** — Predictions and response times. ✅** ****Error Handling** — Exception messages and failures. ## Q8: How do you monitor a deployed ML model? Monitoring a production model involves: 1️⃣** ****Tracking performance metrics** like accuracy, precision-recall, and RMSE. 2️⃣** ****Detecting data drift** by comparing real-time data distributions with training data. 3️⃣** ****Observing model drift** to identify when prediction accuracy declines. 4️⃣** ****Setting alerts for anomalies** using monitoring tools to notify teams of performance degradation. **Popular monitoring tools:** Prometheus, Grafana, Datadog, and Evidently AI. # 4. Testing in ML Pipelines ## Q9: What types of testing are necessary in an ML pipeline? 🔹** ****Unit Testing** — Verifies that individual functions work correctly. 🔹** ****Integration Testing** — Ensures seamless interaction between pipeline components. 🔹** ****Regression Testing** — Confirms that updates do not degrade performance. 🔹** ****Performance Testing** — Evaluates inference speed and scalability. ## Q10: How do you test an end-to-end ML pipeline? End-to-end testing includes: 1️⃣** ****Loading test data** to simulate real-world inputs. 2️⃣** ****Executing the full pipeline** from ingestion to deployment. 3️⃣** ****Validating outputs** to ensure model predictions are accurate. 4️⃣** ****Checking inference performance** to meet service-level agreements (SLAs). # 5. CI/CD for ML Pipelines ## Q11: How does CI/CD work in ML pipelines? CI/CD automates the ML workflow by: ✅** ****Automating model training and validation** to maintain quality. ✅** ****Running performance checks** before deployment. ✅** ****Deploying new models automatically** if they pass quality checks. ✅** ****Rolling back to previous models** when performance drops. **Popular tools:** GitHub Actions, Jenkins, MLflow, Kubeflow. ## Q12: What is a canary deployment, and how does it help in ML pipelines? A** ****canary deployment** releases a new model to a small subset of users before full deployment. This approach: ✔** ****Minimizes risk** by testing the new model with limited users. ✔** ****Enables real-world monitoring** before full rollout. ✔** ****Allows rollback options** if performance declines. # 6. Advanced ML Pipeline Concepts ## Q13: How do you ensure reproducibility in an ML pipeline? Reproducibility ensures consistent results when retraining a model. Best practices include: ✅** ****Versioning code and data** using Git, DVC, or MLflow. ✅** ****Fixing random seeds** in all ML frameworks to maintain consistency. ✅** ****Using containerization** (e.g., Docker) to ensure identical environments. ✅** ****Logging model artifacts** and metadata for reference. ## Q14: What are the biggest challenges in deploying ML models to production? Some key challenges include: 1️⃣** ****Scalability** — Handling large-scale, real-time predictions. 2️⃣** ****Latency** — Meeting strict response time requirements. 3️⃣** ****Model Drift** — Ensuring accuracy over time despite data changes. 4️⃣** ****Resource Optimization** — Managing compute costs effectively. 5️⃣** ****Security & Compliance** — Protecting sensitive data and meeting regulations. ## Q15: How do you handle data drift in an ML pipeline? To detect and address data drift: 📌** ****Monitor feature statistics** to identify shifts in data distribution. 📌** ****Automate retraining** when significant drift is detected. 📌** ****Store feature histories** for comparisons and trend analysis. **Common drift detection techniques:** Kolmogorov-Smirnov test, Wasserstein distance, statistical hypothesis testing. # 7. CI/CD & MLOps in ML Pipelines ## Q16: What is the difference between DevOps and MLOps? DevOps focuses on** ** **software deployment** , whereas MLOps extends DevOps principles to** ** **machine learning models** , covering: ✅** ****Data versioning** in addition to code versioning. ✅** ****Model monitoring** beyond application performance tracking. ✅** ****Automated model retraining** to counteract data drift. ## Q17: What are best practices for scaling ML models in production? 📌** ****Batch Inference** — Processing data in groups rather than in real time. 📌** ****Microservices Architecture** — Deploying models as independent services. 📌** ****Serverless ML** — Using cloud functions for flexible deployments. 📌** ****Model Caching** — Storing frequent predictions for quick retrieval. # 8. Advanced ML Pipeline Architecture & Optimization # Q18: What strategies can be used to optimize an ML pipeline for scalability? To ensure an ML pipeline can scale effectively: ✅** ****Distributed Data Processing** — Use Apache Spark, Dask, or Ray for large datasets. ✅** ****Feature Store Integration** — Implement a centralized feature store to prevent redundant computations. ✅** ****Parallel Processing** — Train models in parallel using GPUs, TPUs, or cloud-based infrastructure. ✅** ****Asynchronous Workflows** — Use message queues (Kafka, RabbitMQ) to decouple pipeline stages. ✅** ****Auto-scaling Infrastructure** — Deploy models in Kubernetes, leveraging auto-scaling mechanisms. # Q19: How do you ensure low latency in real-time ML predictions? Reducing inference latency requires: ✔** ****Model Quantization** — Reducing model size by using lower-precision data types. ✔** ****Optimized Model Serving** — Deploying models using TensorRT, ONNX, or TorchServe. ✔** ****Efficient Feature Serving** — Precomputing and caching frequently used features. ✔** ****Edge Computing** — Deploying models closer to the end user, reducing network overhead. ✔** ****Efficient Request Handling** — Using load balancers to distribute inference requests across multiple instances. # Q20: How do you handle long-running ML training jobs efficiently? For large-scale training jobs: 📌** ****Checkpointing** — Save intermediate training states to resume from failures. 📌** ****Spot Instance Utilization** — Use cloud-based spot instances (AWS, GCP) to reduce costs. 📌** ****Gradient Accumulation** — Optimize memory usage by accumulating gradients over multiple mini-batches. 📌** ****Data Pipeline Optimization** — Use TFRecord, Parquet, or other columnar formats to speed up data loading. # 9. ML Pipeline Monitoring & Observability # Q21: What are the key challenges in monitoring ML models in production? The biggest challenges in ML model monitoring include: 1️⃣** ****Data Drift** — Changes in input data distributions affecting model predictions. 2️⃣** ****Model Drift** — Degradation in prediction accuracy over time. 3️⃣** ****Concept Drift** — Relationship between input features and output labels changes. 4️⃣** ****Latency Issues** — Slow inference due to model complexity or inefficient deployment. 5️⃣** ****Explainability & Bias Detection** — Ensuring fairness and transparency in model predictions. # Q22: What strategies can be used to detect model drift? Model drift can be detected using: ✔** ****Performance Monitoring** — Track key metrics (accuracy, precision, recall, RMSE). ✔** ****Statistical Tests** — Apply Kolmogorov-Smirnov test or Jensen-Shannon divergence to compare distributions. ✔** ****Data Profiling** — Compare feature distributions between training and live data. ✔** ****Automated Alerts** — Set thresholds for drift detection and trigger retraining pipelines. # Q23: How can you improve the observability of an ML pipeline? Observability ensures better insights into ML models and their performance. Best practices include: ✅** ****Centralized Logging** — Collect logs from all pipeline stages for debugging. ✅** ****Telemetry & Tracing** — Use OpenTelemetry to track model behavior across services. ✅** ****Custom Dashboards** — Build visualizations for real-time monitoring (Grafana, Kibana). ✅** ****Explainability Models** — Integrate tools like SHAP and LIME for model interpretability. # 10. MLOps & Governance # Q24: What are the best practices for integrating MLOps into an ML pipeline? MLOps improves ML workflow efficiency through: ✅** ****Continuous Integration (CI)** — Automate testing of feature engineering and model training scripts. ✅** ****Continuous Delivery (CD)** — Deploy models using version control and automation. ✅** ****Automated Retraining** — Trigger new model training when drift is detected. ✅** ****Model Governance** — Enforce compliance through model versioning, explainability, and auditing. # Q25: How do you ensure governance and compliance in ML pipelines? ✔** ****Data Lineage Tracking** — Document data sources, transformations, and usage. ✔** ****Model Documentation** — Maintain audit logs of hyperparameters, training runs, and results. ✔** ****Fairness & Bias Testing** — Evaluate models for potential bias before deployment. ✔** ****Security & Access Control** — Implement role-based access control (RBAC) for sensitive data. # 11. ML Pipeline Deployment & Automation # Q26: What are the differences between batch inference and real-time inference? 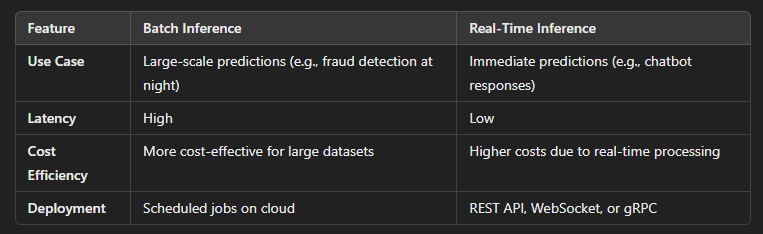 # Q27: How do you automate the retraining of ML models? Automating model retraining involves: ✔** ****Drift Detection** — Monitoring input features for significant changes. ✔** ****Scheduled Retraining** — Periodically retraining the model based on fresh data. ✔** ****Retraining Triggers** — Initiating model retraining when performance drops below a threshold. ✔** ****Retraining Pipelines** — Using CI/CD for model updates, testing, and deployment. # Q28: How do you handle A/B testing for ML models in production? A/B testing allows comparison between multiple models before full deployment. Best practices include: 📌** ****Traffic Splitting** — Serving different model versions to different user groups. 📌** ****Metric Tracking** — Comparing accuracy, latency, and user engagement across variants. 📌** ****Gradual Rollout** — Deploying models incrementally to monitor real-world performance. 📌** ****Rollback Strategies** — Reverting to the previous model if the new version underperforms. # 12. Security & Ethical Considerations in ML Pipelines # Q29: How do you ensure security in an ML pipeline? ✔** ****Data Encryption** — Protect data at rest and in transit. ✔** ****Access Control** — Restrict access to sensitive models and datasets. ✔** ****Adversarial Testing** — Test models against adversarial inputs to detect vulnerabilities. ✔** ****Model Watermarking** — Embed unique identifiers to detect unauthorized use. # Q30: How do you mitigate bias in ML models? 📌** ****Diverse Training Data** — Ensure datasets are representative of the population. 📌** ****Bias Audits** — Regularly evaluate models using fairness metrics (e.g., disparate impact analysis). 📌** ****Explainability Methods** — Use SHAP or LIME to understand model decisions. 📌** ****Human-in-the-loop Review** — Incorporate domain experts to validate model predictions.
cd iam-lifecycle-demo
**Transformar website genérico em plataforma profissional de venda para Rafaella Kally (Terapeuta de Reiki Kundalini)**
- **Server:** Hetzner CPX22 VPS in Nuremberg (nbg1), `188.245.75.73`
CURRENT PRIORITIES AS OF 2025 01 13 @ 21:50