Back to Blog hackathon
hackathon kubernetes
kubernetes ai
ai typescript
typescript showdev
showdev ai
ai agents
agents
Gaffa @ Major League Hacking's Global Hack Week
James May 1, 2026
0 views
Every month, Major League Hacking (MLH) hosts a Global Hack Week, a free event where developers can...
**Every month, [Major League Hacking (MLH)](https://mlh.io/) hosts a [Global Hack Week](https://ghw.mlh.io/), a free event where developers can learn new skills, build their portfolios, and connect with other hackers. MLH is the world’s largest developer community with over 5M software creators living throughout 100+ countries. Every year, MLH hosts 1000+ events online and in-person where community members come together to learn, build, and share the latest and greatest technology.**
**We were invited to present at Global Hack Week Cloud, where I ran a live session introducing [Gaffa](https://gaffa.dev?utm_source=devto&utm_medium=blog&utm_campaign=mlh-ghw) and how it makes building with web data significantly easier. Below are the key moments from the session.**
{% embed https://www.youtube.com/watch?v=SMICXc-78a8 %}
## ▶️ [What is web scraping and why does it matter?](https://www.youtube.com/live/SMICXc-78a8?si=mexOM9Ep7YtkDylS&t=830)
I opened the session by covering the fundamentals of web scraping, the practice of extracting data from websites that don't offer an API. The internet is the world's largest database, but most of it isn't neatly packaged for developers, and scraping is getting harder every year. Modern JavaScript frameworks mean pages often don't include their data in the initial HTML response, and many sites actively detect and block automated requests. Tools like Playwright, Selenium, and BeautifulSoup have long been the go-to stack, but they require significant setup, maintenance, and infrastructure to run reliably at scale.
We also touched on the legal question that arises whenever scraping is discussed. Scraping publicly accessible data is generally accepted and widely used across industries, from price comparison to financial data feeds to AI training sets. The areas to avoid are personal data, content behind a login, and anything that puts undue load on a site, particularly smaller, nonprofit ones.
## ▶️ [Introducing Gaffa and the API playground](https://www.youtube.com/live/SMICXc-78a8?si=qW7avTw2HV9XJIM0&t=1776)

The session then moved into a walkthrough of [Gaffa](https://gaffa.dev?utm_source=devto&utm_medium=blog&utm_campaign=mlh-ghw) itself. Gaffa is a web browser automation API. You send a POST request with a URL and a list of actions, and Gaffa executes them in a real, hosted browser and returns the result. No infrastructure to manage, no proxies to configure, no bot detection to fight.
The [API Playground](https://gaffa.dev/dashboard/playground?utm_source=devto&utm_medium=blog&utm_campaign=mlh-ghw) is the best place to get started. It lets you build and test browser requests interactively, with built-in examples covering common scenarios. During the session, I walked through a live form-filling example, including enabling request recording so you can see exactly what the browser did.
## ▶️ [Demo: Scraping a webpage and asking questions with AI](https://www.youtube.com/live/SMICXc-78a8?si=WD65TSWxHbbp7QVu&t=2317)
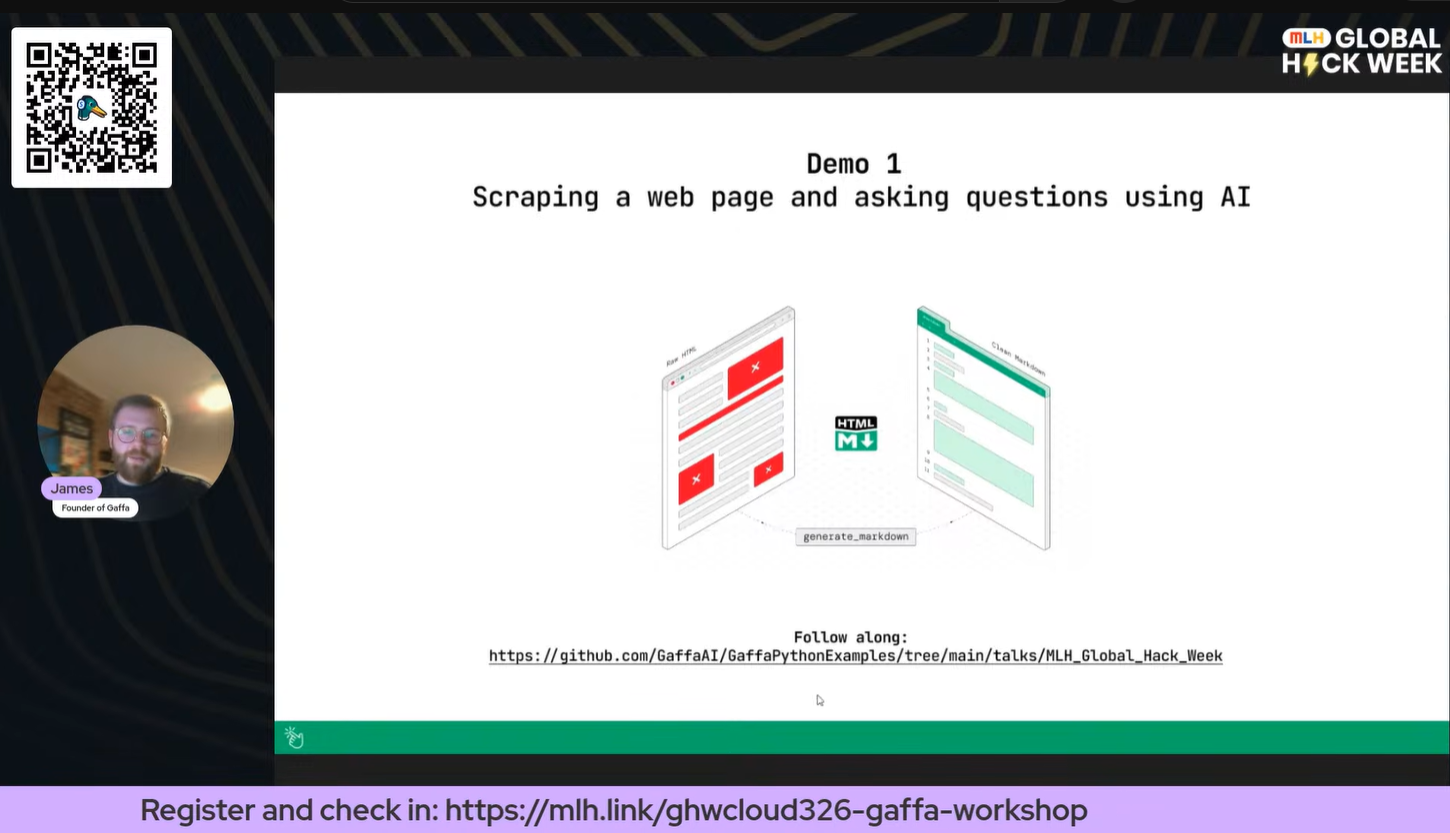
The first full demo showed how to scrape a Wikipedia article and use it as context for an OpenAI Q&A session. The workflow is straightforward: use Gaffa's [*generate_markdown*](https://gaffa.dev/docs/features/browser-requests/actions/generate-markdown?utm_source=devto&utm_medium=blog&utm_campaign=mlh-ghw) action to strip a page down to clean, LLM-ready text, then pass that markdown to the model with a question.
The key insight here is that markdown is a much more efficient way to feed web content into a language model than raw HTML. It removes noise while preserving the page's structure and meaning. The demo showed the model correctly answering questions about the article content and, importantly, telling us when an answer wasn't present, a behavior we prompted for explicitly.
The full example is available in the [Gaffa Python Examples GitHub repository](https://github.com/GaffaAI/GaffaPythonExamples/blob/main/talks/MLH_Global_Hack_Week/webpage_to_markdown_and_qa.ipynb).
## ▶️ [Demo: Extracting structured data with *parse_json*](https://www.youtube.com/live/SMICXc-78a8?si=RMobTJ20od-Ksh4K&t=2728)
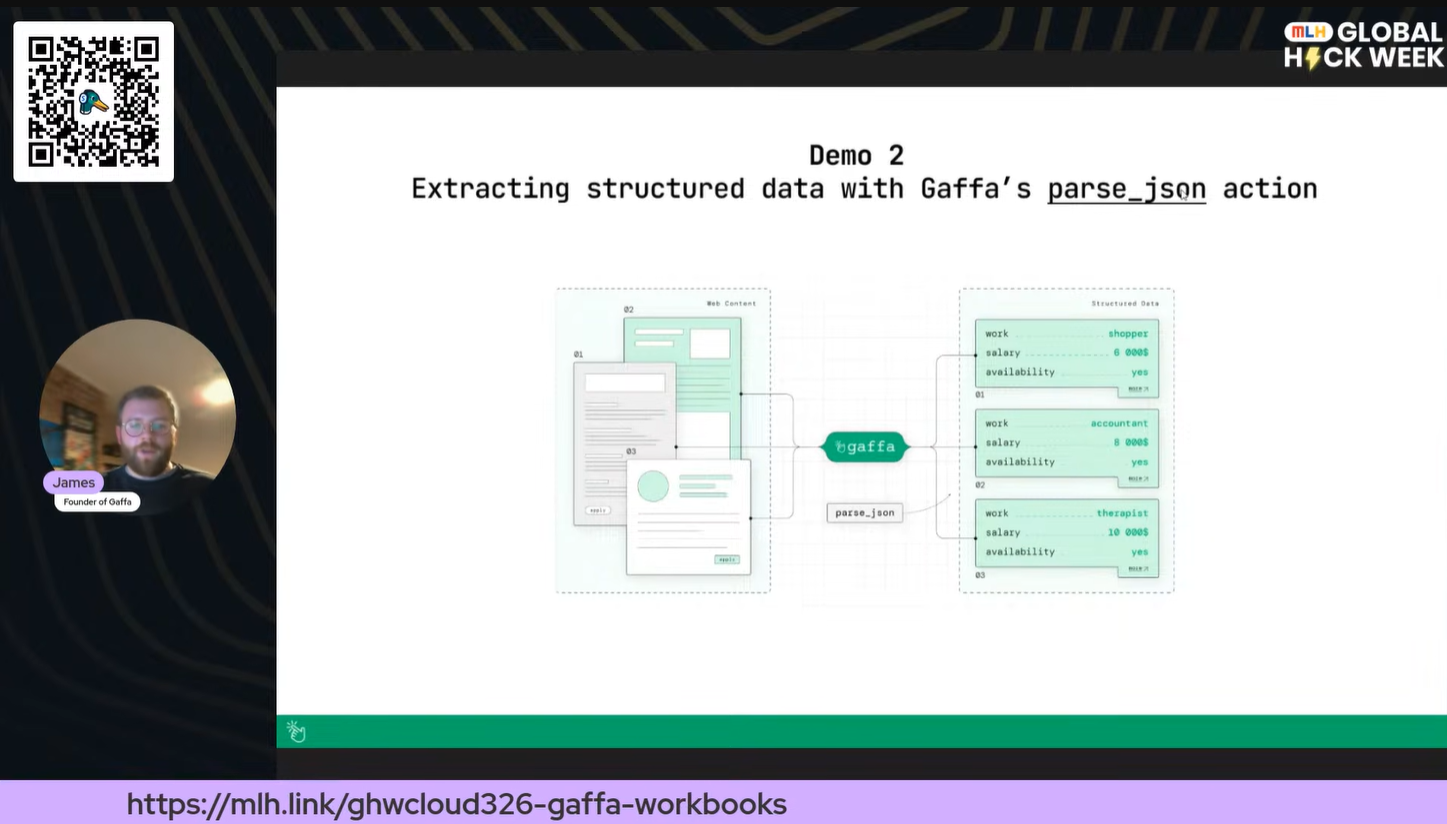
The second demo is where things get particularly powerful. Rather than asking free-form questions, [*parse_json*](https://gaffa.dev/docs/features/browser-requests/actions/parse-json?utm_source=devto&utm_medium=blog&utm_campaign=mlh-ghw) lets you define a data schema and have Gaffa use an AI model to extract exactly the fields you need from any page, regardless of its structure.
In the session, I used the Python Wikipedia page as an example, extracting the title, creator, release year, summary, and key features. The schema is defined as a JSON object with named fields, types, and per-field descriptions that act as mini-prompts to guide the model.
One practical detail that came up with a real client: you can use field descriptions to enforce a specific output format, for example, specifying that a country field should return a two-letter ISO Alpha-2 code rather than whatever format appears on the page. The model handles the mapping automatically.
The same action also works on online PDFs. I demonstrated this against a hosted academic paper, extracting the title, abstract, author names, and institutional affiliations, the kind of data that varies in layout across every paper you'd encounter, making it almost impossible to extract reliably with traditional selectors. The result was a clean JSON object ready to insert directly into a database.
Both examples are available in the [Gaffa Python Examples GitHub repository](https://github.com/GaffaAI/GaffaPythonExamples/blob/main/talks/MLH_Global_Hack_Week/structured_data_extraction_with_parse_json.ipynb).
## ▶️ [The MLH challenges](https://www.youtube.com/live/SMICXc-78a8?si=Y7Ix85DucmUDmvpM&t=3462)

As part of Global Hack Week, we put together a set of Gaffa challenges for attendees:
- Sign up for a Gaffa account and redeem the MLH credit code for $20 of free credits
- Send your first request in the API Playground
- Use a browser request to subscribe to our newsletter via the [Gaffa demo site](https://demo.gaffa.dev/mlh/challenge?utm_source=devto&utm_medium=blog&utm_campaign=mlh-ghw)
- Extract the title, summary, and author from a Gaffa blog post using *parse_json*
If you're working through these and run into any issues, reach out via support, and we'll help you get unstuck.
> Had a great experience with Gaffa! It was my first time doing browser automation, and sending that first API request to print an HTML page to PDF felt like magic. The step-by-step challenges made a complex topic really approachable.
> — A Global Hack Week participant
A huge thank you to the MLH team, particularly Rosendo, for hosting the opportunity to present to their community. It was a genuinely great audience, full of thoughtful questions about scraping legality, dynamic sites, speed, and cost. If you were in the session or are just now finding this post, thanks for watching and reading.
**If you want to try everything covered in the session, [sign up for a free Gaffa account](https://gaffa.dev?utm_source=devto&utm_medium=blog&utm_campaign=mlh-ghw) and head to the API Playground to make your first request. The demo site, Python examples, and documentation are all there waiting for you.**
Comments
More Blog
View allkubernetesMinimalist EKS: The Easy Way
Amazon EKS manages the Kubernetes control plane, but you remain responsible for provisioning the...
J
Joaquin MenchacaaiNever forget to enter the Stern Grove lottery again!
Browser automation with Playwright, Python, GitHub Actions, and Entire to auto-enter San Francisco Stern Grove concert lotteries each week!
L
Lizzie SiegletypescriptA Free Screenshot Editor That Never Uploads Your Image
A free screenshot and image editor that runs entirely in your browser. Keeping every edit reversible and handling big phone photos, in plain TypeScript and Canvas2D.
M
Martin StarkshowdevI built a CLI to break my highlights out of Apple Books
A macOS CLI + MCP server that exports Apple Books highlights to Markdown and gives AI assistants direct access to your reading notes.
A
Andrey KorchakaiA Developer's Guide to Agent Hooks in Antigravity CLI
Motivation To be quite honest, "Hooks"—the shell commands we trigger at specific points...
T
TanaikeagentsTactical vs. Strategic Agentic AI Development — A Playbook for Developers
The Strategic Engineer: Why Writing Code Is No Longer Your Most Valuable Skill ...
A
Adewumi Saheed Adewale