Back to Blog aws
aws
 gemma
gemma community
community ai
ai ai
ai githubactions
githubactions ai
ai
The Build-to-Learn Framework: How a Near-Disaster Taught Me to Learn in Public
Martín Rivadavia February 4, 2026
0 views
I almost created an infinite loop that would have cost thousands. Documentation saved me. Here's the framework that emerged.
title: "The Build-to-Learn Framework: How a Near-Disaster Taught Me to Learn in Public" published: true description: I almost created an infinite loop that would have cost thousands. Documentation saved me. Here's the framework that emerged. tags: aws, amazonbedrock, generativeai, learninpublic cover_image: https://raw.githubusercontent.com/rivadaviam/aws-genai-cert-learning-journey/main/_bmad-output/blog-articles/cover-devto.png canonical_url: https://github.com/rivadaviam/aws-genai-cert-learning-journey series: Build-to-Learn with AWS GenAI
{kind=link}
I almost created an infinite loop that would have cost me thousands in AWS bills.
And I'm grateful it almost happened.
The Setup
When I decided to pursue the AWS Certified Generative AI Developer certification, I made myself a promise: I wouldn't just study for an exam. I would build real systems, make real mistakes, and share everything publicly—including the wrong turns.
The AWS Skill Builder course has these "Bonus Assignments" scattered throughout. Most people skip them or treat them as quick checkboxes.
I saw something different: each one was an invitation to build something production-ready.
My first assignment: an automated insurance claim processing pipeline using Amazon Bedrock.
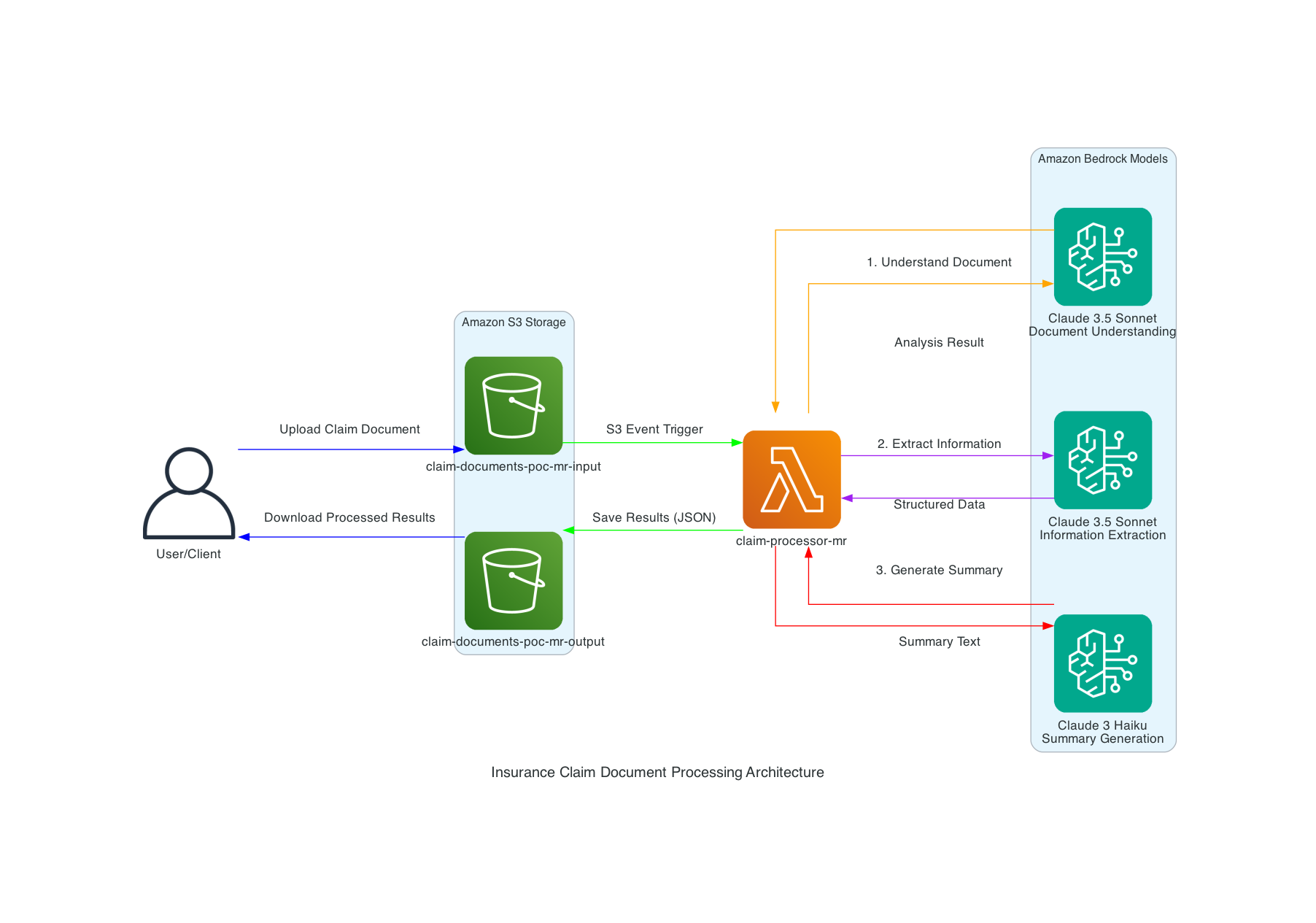 User uploads to S3 → Lambda orchestrates 3-step Bedrock pipeline → Results saved to output bucket
User uploads to S3 → Lambda orchestrates 3-step Bedrock pipeline → Results saved to output bucket
The Near-Disaster
My initial architecture was elegant. One S3 bucket, two prefixes:
/inputfor uploaded documents/outputfor processed results
Clean. Simple. Catastrophic.
Here's what happens with that design:
1. Document lands in /input
2. Lambda triggers, processes document
3. Result written to /output (same bucket)
4. S3 event triggers Lambda again
5. Lambda processes the output file...
6. → Infinite loop. Infinite cost.
I caught this because I was writing an Architecture Decision Record—ADR-002—explaining my bucket strategy.
The act of documenting forced me to think through the consequences. Mid-sentence, I realized what would happen in production.
# ADR-002: Separate S3 Buckets for Input and Output
## Decision
Use separate S3 buckets for input and output
## Consequences
- Prevents infinite loop scenarios
- Better security isolation
- Different lifecycle policies per bucket
- Slight increase in bucket management complexity
## Why This Choice
Following AWS best practices prevents production issues.
The slight complexity increase is worth avoiding infinite loops.
That ADR saved me real money. But more importantly, it taught me something:
Documentation isn't overhead. It's thinking made visible.
The Build-to-Learn Framework
That near-miss crystallized into a methodology I now follow for every lab: build real things, document every decision, and share the messy middle.
Not tutorials. Not sandboxes. Production-grade systems with real constraints — the kind where a wrong architecture choice costs actual money. For every significant decision, I write an Architecture Decision Record capturing the why, not just the what. And when I share the work, I don't polish away the wrong turns. The trade-offs, the moments of doubt, the diagrams I scrapped at midnight — those are the parts that actually help someone else learn.
The Implementation
Instead of one monolithic prompt, I designed a three-step AI pipeline where each step uses the optimal model:
| Step | Model | Why |
|---|---|---|
| Document Understanding | Claude 3.5 Sonnet | Complex reasoning needed |
| Information Extraction | Claude 3.5 Sonnet | Precision for structured JSON |
| Summary Generation | Claude 3 Haiku | Cost-efficient for simple output |
Step 1: Document Understanding
def process_document_understanding(document_text, model_id, template_manager):
"""Analyze and understand the document structure and content."""
prompt = template_manager.get_prompt(
"document_understanding",
document_text=document_text
)
return invoke_bedrock_model(
model_id,
prompt,
temperature=0.1, # Low temperature for accuracy
max_tokens=2000
)
Why this step? Complex documents need context before extraction. Understanding the document type (auto claim vs. health expense) improves downstream accuracy.
Step 2: Information Extraction
def extract_information(document_text, model_id, template_manager):
"""Extract structured information from the document."""
prompt = template_manager.get_prompt(
"extract_info",
document_text=document_text
)
result = invoke_bedrock_model(
model_id,
prompt,
temperature=0.0, # Zero temperature for deterministic output
max_tokens=1500
)
return result
Key insight: Using temperature=0.0 ensures consistent, deterministic extraction. This matters when downstream systems depend on specific JSON fields.
Step 3: Summary Generation
def generate_summary(extracted_info, model_id, template_manager):
"""Generate a concise summary of the claim."""
prompt = template_manager.get_prompt(
"generate_summary",
extracted_info=extracted_info
)
return invoke_bedrock_model(
model_id,
prompt,
temperature=0.7, # Higher temperature for natural language
max_tokens=500
)
Why Haiku here? The heavy lifting is done. We're just formatting extracted data into prose. Claude 3 Haiku does this well at ~10x lower cost than Sonnet.
This decision is captured in ADR-005:
# ADR-005: Use Claude 3 Haiku for Summary Generation
## Decision
Use Claude 3 Haiku for summary generation (not Sonnet)
## Rationale
- Summaries are the final step - context is already extracted
- Haiku is ~10x cheaper than Sonnet
- Quality is sufficient for 2-3 sentence summaries
- Maintains on-demand throughput support
## Trade-off
Slight quality reduction for significant cost savings
Model Selection: The Certification Question
If you're preparing for AIP-C01, model selection is a core exam topic — and this project gave me a real-world taste of the trade-offs involved.
One decision surprised me. Claude 3.5 Sonnet v2 is newer and, on paper, "better" than v1. But when I dug into availability, I discovered that on-demand throughput isn't guaranteed in all regions and might require Provisioned Throughput. For a learning project that other developers will clone and deploy in their own accounts, availability matters more than marginal quality improvements. So I chose v1 — a stable, widely available model that anyone can spin up without provisioning headaches. It was a small decision, but exactly the kind of reasoning the certification expects you to articulate.
The Infrastructure
The entire stack is defined in Terraform, which means anyone can deploy it with a single terraform apply. Here's the Lambda at the heart of it:
resource "aws_lambda_function" "processor" {
function_name = "${var.project_name}-processor"
runtime = "python3.12"
handler = "lambda_handler.handler"
timeout = 300 # 5 minutes
memory_size = 512 # MB
environment {
variables = {
OUTPUT_BUCKET = aws_s3_bucket.output.id
BEDROCK_MODEL_UNDERSTANDING = "anthropic.claude-3-5-sonnet-20240620-v1:0"
BEDROCK_MODEL_EXTRACTION = "anthropic.claude-3-5-sonnet-20240620-v1:0"
BEDROCK_MODEL_SUMMARY = "anthropic.claude-3-haiku-20240307-v1:0"
}
}
}
The numbers tell a story. A typical run — three sequential Bedrock calls — takes 30 to 90 seconds, but I set the timeout to 5 minutes to absorb cold starts, larger documents, and network latency. Memory sits at 512 MB: enough headroom for boto3 and JSON processing without overpaying for capacity the function will never touch. Both values came from testing, not guessing — another benefit of building before theorizing.
What I Learned (Beyond the Tech)
The biggest surprise wasn't technical — it was how much the act of writing things down changed my engineering decisions. ADRs forced me to justify every choice, and several times I reversed course mid-sentence because explaining a decision out loud revealed the flaw in it. Documentation isn't a chore you do after the code works; it's a design tool you use while the code is still taking shape.
Building locally first saved me real money, too. The system supports running the full pipeline on your own machine (python main.py --input claim.txt --output result.json), so I processed dozens of test documents before a single Lambda invocation or Bedrock API call ever hit my AWS bill.
And here's what connected everything back to the certification: every core topic from the Skill Builder course — model selection criteria, prompt engineering, cost optimization, security best practices, serverless patterns — showed up organically in this one project. I didn't have to memorize them. I had to use them, and that made them stick.
What's Next
This is just the beginning. I'm continuing to build through the AWS GenAI certification curriculum, turning each challenge into a production-ready implementation. More labs are coming — each one following the same Build-to-Learn principles: production-ready code you can actually deploy, every decision documented with ADRs, and the messy middle shared so you learn from my mistakes too.
Want to follow along? Star the repo or connect with me on LinkedIn to get notified when the next lab drops.
Try It Yourself
The entire project is open source. Clone it, read the ADRs, poke around the Terraform — and if you find a flaw in my implementation, open an issue. If you have a better approach, propose it.
{% github rivadaviam/aws-genai-cert-learning-journey %}
# Clone and explore
git clone https://github.com/rivadaviam/aws-genai-cert-learning-journey.git
cd labs/lab-01-claims-doc-processing
# Read the full guide
cat README.md
# Deploy with Terraform
cd infra/terraform
terraform init && terraform apply
The Invitation
If you're preparing for a certification, don't just study. Build something real. Document your decisions. Share your journey. And if you build something using this framework, tell me about it — I want to see what you create.
Certifications prove you can learn. Projects prove you can build. Documentation proves you can teach.
The Build-to-Learn Framework asks: why not do all three?
Have questions? Connect with me on LinkedIn or drop a comment below.
Build. Document. Share. Repeat.
#BuildToLearn #AWSCommunity #LearnInPublic
Comments
More Blog
View allgemmaFive Gemma-4 models, one accelerator: what porting E2B 31B to AWS Inferentia2 taught me
I ported the whole Gemma-4 family — E2B, E4B, 12B, 31B, and the 26B-A4B MoE — to run on...
X
xbillcommunityHey DEV, I'm Tobore. Let's actually connect.
Hey DEV, I'm Tobore. Let's actually connect. I've been on here for a while now, mostly writing and...
L
Laurina AyarahaiI burned through thousands of AI tokens. Then a friend did it for free
(yep, kinda clickbait, just for the funsies 😊) At the beginning of the year, I relaunched my...
P
Paulo HenriqueaiClaude might be saturating your machine
My laptop was sitting idle with the fan at full tilt. Nothing was running that I knew of. The culprit...
S
Sidhant PandagithubactionsAutomated GitHub Code Reviews Using Google Gemini
I Built a Thing! TL;DR — Google Gemini-based Pull Request reviews and Issue Triaging for...
D
Darren "Dazbo" LesteraiWhat is an "agentic harness," actually?
I've been hearing the word "harness" thrown around a lot lately. I assumed it just meant "the IDE" or...
T
Tilde A. ThuriumReady-made automations for this
Workflows from the Neura Market marketplace related to this DeepSeek resource
- Build an AI Documentation Expert Bot Using RAG, Gemini, and Supabasen8n · $24.99 · Related topic
- n8n Documentation: Expert Chatbot with OpenAI RAG Pipelinen8n · $24.99 · Related topic
- Auto-generate Documentation for n8n Workflows with GPT and Docsifyn8n · $24.99 · Related topic
- Answer Questions About Documentation with BigQuery, RAG, and OpenAIn8n · $14.99 · Related topic