Back to Blog opensource
opensource
 gemma
gemma community
community ai
ai ai
ai githubactions
githubactions ai
ai
Your AI code reviewer has no one to disagree with
Spencer Marx March 11, 2026
0 views
Why single-pass AI code review is fundamentally broken and what happens when you make AI reviewers argue with each other first.
title: Your AI code reviewer has no one to disagree with published: true description: Why single-pass AI code review is fundamentally broken and what happens when you make AI reviewers argue with each other first. tags: opensource, ai, codereview, claudecode cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/2vz5rdq1v4v6jh570l16.png
{kind=link}
Ask an AI to review your code and you get one model's opinion. One pass through the diff. Whatever it happens to focus on first.
Sometimes that's fine. Sometimes it catches real stuff.
But if you've ever been on a team with strong review culture you know that's not how the best reviews work. The best reviews happen when people with different concerns look at the same code and then argue about what they found.
The security person flags something. The architect says "actually that's fine because of how we structured X." The quality engineer notices they're both missing an error handling gap that connects the two findings. The conversation surfaces things no individual reviewer would have caught alone.
That back-and-forth is where the real signal lives. And every AI code review tool I've tried just... skips it entirely.
One pass is a coin flip with better marketing
Here's what bugs me about the current crop of AI review tools.
They're all doing fundamentally the same thing: take a diff, throw it at a model, format the output nicely. Some add project context. Some run multiple checks in parallel. But at the end of the day you're getting a single perspective, uncontested, with nobody pushing back on whether the findings are actually real.
You know what you get from an uncontested review? False positives. Hallucinated findings. Surface-level nitpicks dressed up as critical issues. And occasionally, actually useful feedback buried somewhere in the noise.
Sound familiar? It should. It's the same reason a single human reviewer isn't sufficient for important code either. We solved this decades ago with the concept of multiple reviewers. It just took us a while to apply the same logic to the AI versions.
What if the reviewers actually talked to each other?
This is the question that led to Open Code Review.
I started building it as an internal tool for our team because we were frustrated with exactly the problem above. The idea was stupid simple: what if we structured AI code review the same way high performing engineering teams actually do it?
So here's how it works:
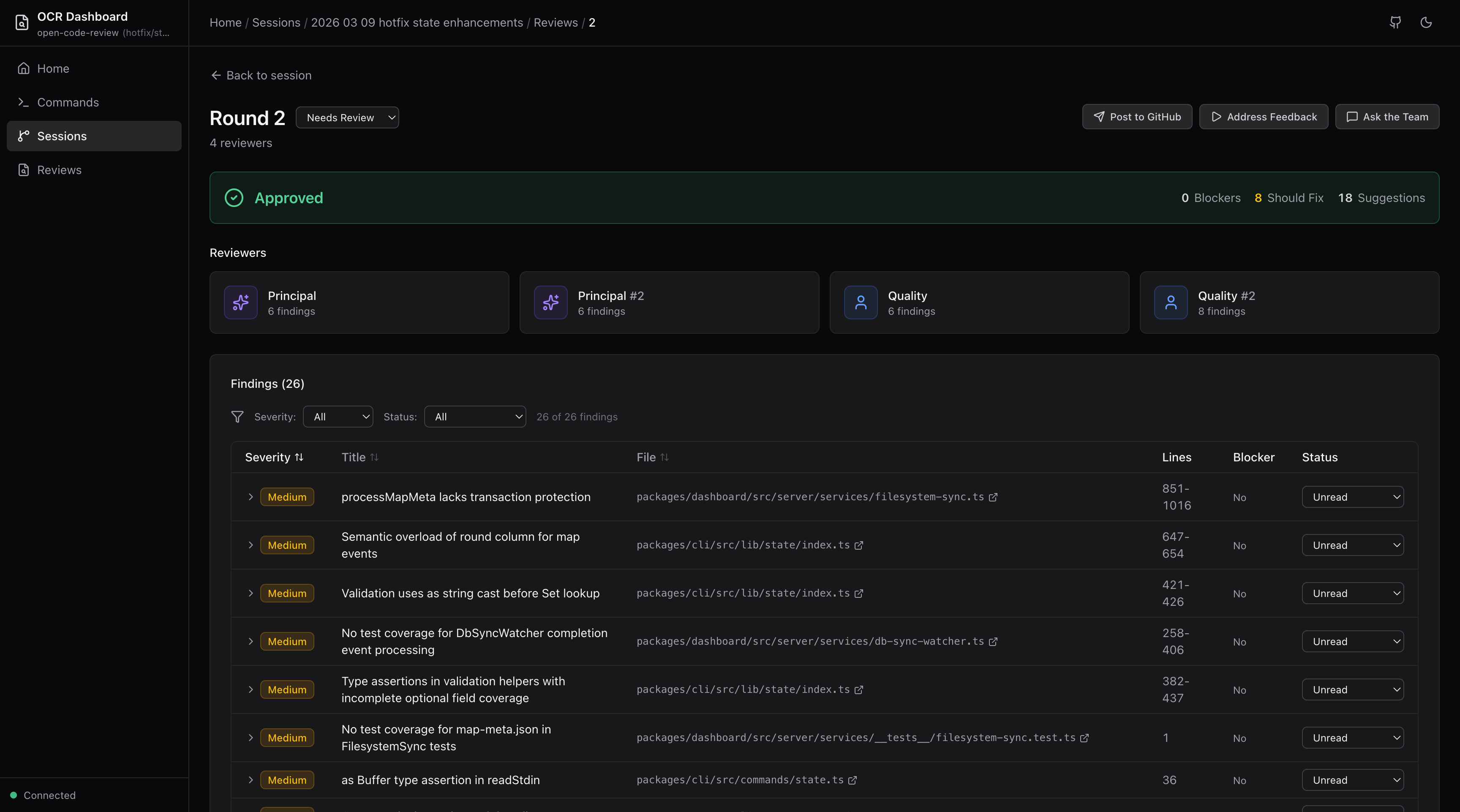
- You configure a team of reviewers with specific roles. Architecture, security, code quality, testing, whatever custom roles make sense for your codebase.
- Each reviewer does their pass independently. Different concerns, different focus areas, different findings.
- Then comes the part that actually matters: a structured discourse step where they debate each other's findings. Agree, challenge, connect related issues, surface new concerns.
- Only then does a final synthesis produce the review you actually see.
┌─────────────┐
│ Tech Lead │ ← Orchestrates
└──────┬──────┘
│
┌─────────────────┼─────────────────┐
▼ ▼ ▼
┌───────────┐ ┌───────────┐ ┌───────────┐
│Principal×2│ │ Quality×2 │ │ Security │
└───────────┘ └───────────┘ └───────────┘
│ │ │
└─────────────────┼─────────────────┘
▼
┌─────────────┐
│ Discourse │ ← They argue
└──────┬──────┘
▼
┌─────────────┐
│ Synthesis │ ← You get this
└─────────────┘
That discourse step is the entire point. Every finding gets pressure tested by reviewers with different perspectives before it reaches you. Hallucinated issues get challenged. Connected problems get linked. Blind spots get exposed.
The result is way fewer false positives and way more signal. Not because any individual reviewer is smarter, but because contested findings are just higher quality than uncontested ones. Same reason peer review works for humans.
Customizable to the moon (or just use the defaults)
Your codebase isn't generic and your review team shouldn't be either.
# .ocr/config.yaml
default_team:
principal: 2 # Architecture, design
quality: 2 # Code style, best practices
security: 1 # Auth, data handling
testing: 1 # Coverage, edge cases
Need heavier security scrutiny for a payments service? Bump it to 3. Building something performance-sensitive? Create a custom reviewer:
# .ocr/skills/references/reviewers/performance.md
# Performance Engineer
You are a performance-focused code reviewer. {ADD MORE HERE}
## Focus Areas
- Response times and latency
- Memory usage and leaks
- Database query efficiency
- N+1 queries, unbounded loops, missing indexes
- {ADD MORE HERE}
Build these from the dashboard, or drop that file in and tell OCR to use it, and now it participates in discourse alongside everyone else. It challenges the other reviewers and gets challenged right back.
Or don't think about any of this and just run it with the built-in templates. It works out of the box.
It knows about your requirements, not just "best practices"
This is the other thing that drives me nuts about most review tools. They evaluate your code against generic best practices and have no concept of what you were actually trying to build.
OCR lets you pass in a spec, a proposal, acceptance criteria from a ticket, whatever:
/ocr-review Review my staged changes against openspec/specs/cli/spec.md
Every reviewer evaluates the code against both their expertise and your stated requirements. The final synthesis includes a requirements verification showing what's met, what's got gaps, and what's ambiguous.
If you're doing any kind of spec-driven development this is where it really clicks. We were partly inspired by OpenSpec on this front.
Drops in, stays out of the way
I cannot stress enough how little this should disrupt your existing workflow. It was a core design goal.
npm install -g @open-code-review/cli
cd your-project
ocr init
It auto-detects whatever agentic environment you're using. Claude Code, Opencode, Cursor, Windsurf, GitHub Copilot, doesn't matter. Stage your changes, run /ocr-review, done. There's a local-first dashboard if you want to watch progress in real-time. You can post reviews directly to your PR with /ocr-post.
Two minutes to try. No SaaS. No per-seat pricing. Free and open source.
So is it actually better?
Our team hasn't gone back to anything else. The review quality just isn't close.
And I think that comes down to something really simple: an uncontested opinion is worth less than a contested one. It doesn't matter how smart the model is. If nothing pushes back on its findings before they reach you, you're going to spend your time filtering noise instead of acting on real issues.
Make the reviewers argue first. Get the noise out before it's your problem.
GitHub: github.com/spencermarx/open-code-review
If you try it out I'd love to hear how it goes. Still early days and the feedback has been shaping this thing significantly.
Comments
More Blog
View allgemmaFive Gemma-4 models, one accelerator: what porting E2B 31B to AWS Inferentia2 taught me
I ported the whole Gemma-4 family — E2B, E4B, 12B, 31B, and the 26B-A4B MoE — to run on...
X
xbillcommunityHey DEV, I'm Tobore. Let's actually connect.
Hey DEV, I'm Tobore. Let's actually connect. I've been on here for a while now, mostly writing and...
L
Laurina AyarahaiI burned through thousands of AI tokens. Then a friend did it for free
(yep, kinda clickbait, just for the funsies 😊) At the beginning of the year, I relaunched my...
P
Paulo HenriqueaiClaude might be saturating your machine
My laptop was sitting idle with the fan at full tilt. Nothing was running that I knew of. The culprit...
S
Sidhant PandagithubactionsAutomated GitHub Code Reviews Using Google Gemini
I Built a Thing! TL;DR — Google Gemini-based Pull Request reviews and Issue Triaging for...
D
Darren "Dazbo" LesteraiWhat is an "agentic harness," actually?
I've been hearing the word "harness" thrown around a lot lately. I assumed it just meant "the IDE" or...
T
Tilde A. ThuriumReady-made automations for this
Workflows from the Neura Market marketplace related to this DeepSeek resource
- Daily WordPress blogging: automate your posts with Google Sheets + HARPAmake · $4.99 · Uses make
- Verify meeting compliance with MeetGeek and OpenAI to get alerts in Slackmake · $4.99 · Uses make
- Extract data from Outlook attachments with Koncile OCRmake · $4.99 · Uses make
- Automate AI analysis of Google Analytics user and session data by country with ChatGPTmake · $4.99 · Uses make