Back to Blog java
java
 gemma
gemma community
community ai
ai ai
ai githubactions
githubactions ai
ai
Scaling ID Generation with Redis
Krishna Tej Chalamalasetty March 26, 2026
0 views
It Started with a Simple Counter I work on a cloud-based document management platform used...
It Started with a Simple Counter
I work on a cloud-based document management platform used by large construction and engineering firms. Every document uploaded drawings, RFIs, approvals gets an unique ID following a tenant-defined schema:
PROJ-9012-1001
│ │ │
│ │ └── Sequence number (auto-incremented)
│ └──────── Document type identifier
└──────────────── Project code
An internal microservice called id-generator handled this. It worked fine for years, a closed system behind our portal, moderate traffic, no drama.
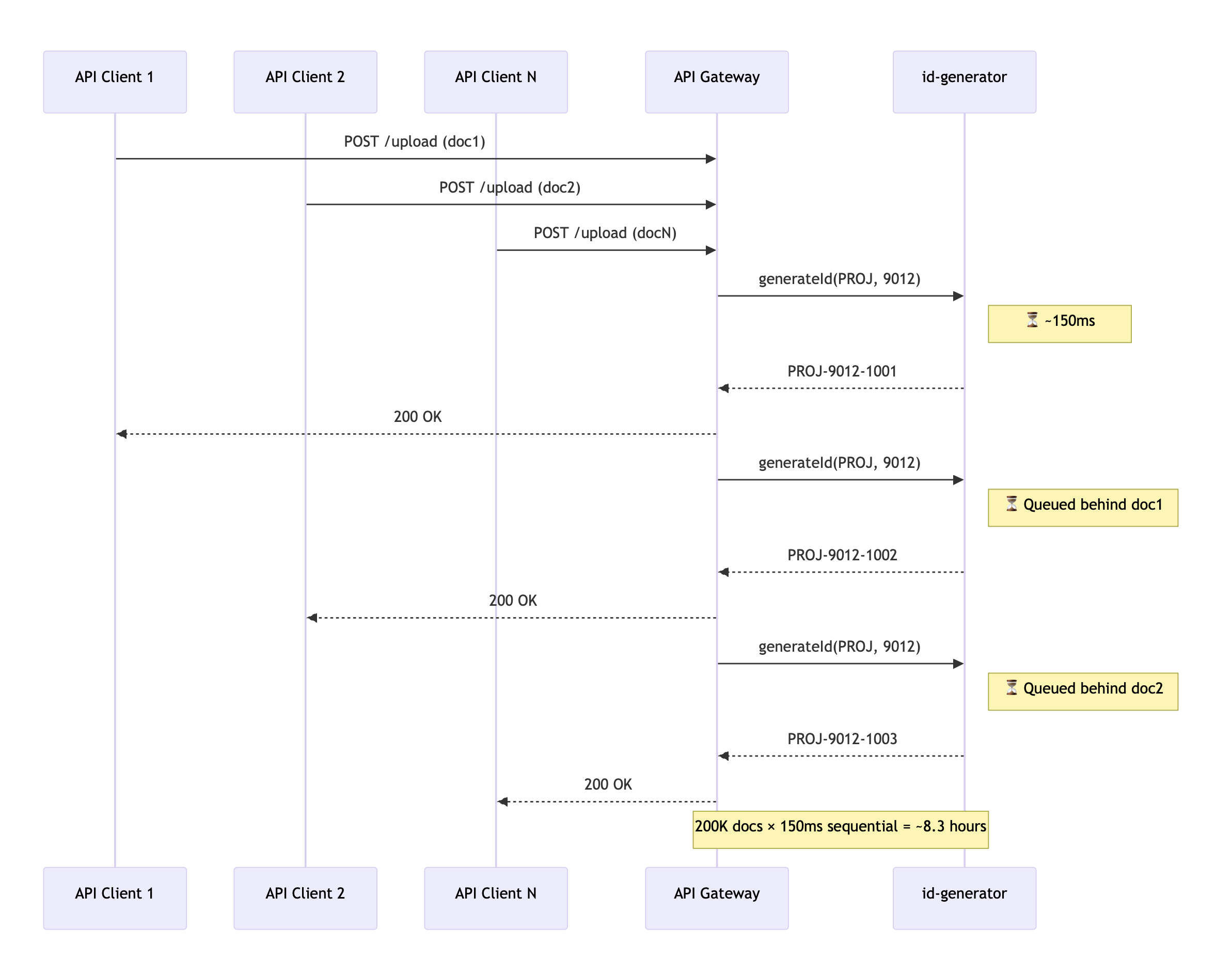
Then we opened Public APIs so customers could automate their workflows. And the first large customer tried to migrate 200,000 documents in a single batch.
The id-generator was called once per document, sequentially. Each call was a network hop. The migration ran for over six hours. The customer was not pleased.
Why Sequential Doesn’t Scale: The Math
A single ID generation involves a network round-trip to the id-generator (~100ms) plus the generator’s own processing and sequence counter commit (~50ms). Call it 150ms per ID.
For 200,000 documents, sequential processing means:
200,000 × 150ms = 30,000 seconds ≈ 8.3 hours
"Just add more app instances" doesn’t help. We can spread requests across three instances behind a load balancer, but all three call the same id-generator. The generator processes one request at a time to guarantee sequential numbering. The bottleneck isn’t the app layer, it’s the single-threaded sequence generation.
Even if I made the id-generator handle **10 concurrent requests **(with database level locking on the counter):
200,000 ÷ 10 concurrent × 150ms = 3,000 seconds ≈ 50 minutes
Better, but fragile. The id-generator becomes a high contention hotspot, and any slowdown cascades to every project uploading at the same time.
I needed to decouple ID consumption from ID generation entirely, serve IDs without waiting for the generator.
The Architecture
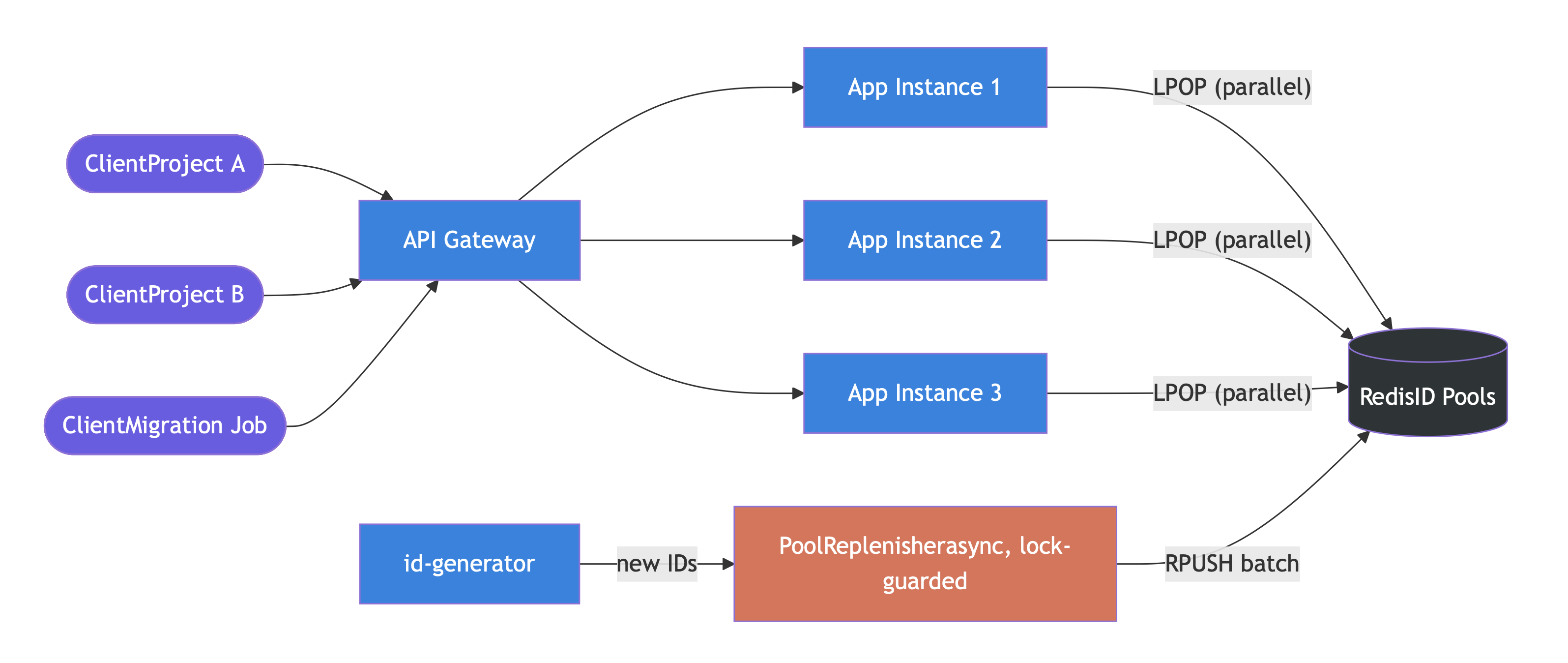
This is a classic producer-consumer problem. Thousands of clients across different projects and organizations fire upload requests through an API gateway. The gateway distributes traffic across multiple app instances. But all instances need IDs from the same sequence space per (project, documentType), and a single producer (the id-generator) feeds that space.
The insight: if I pre-generate IDs in bulk and stash them in a shared store, the app instances become consumers popping from a ready made pool, while the id-generator becomes a background producer that refills the pool asynchronously. Consumers never wait for the producer. The pool is the buffer that decouples them. I chose Redis as that shared store.
##The Fix: Pre-populated ID Pools in Redis
The idea is straightforward. Instead of generating an ID when a request arrives, generate them ahead of time and stash them in Redis.
When a request comes in, pop one off the list. No waiting.
Each (project, documentType) combination gets its own Redis List:
Key: id-pool:PROJ:9012
Value: ["1001", "1002", "1003", ..., "2000"] ← 1000 pre-generated IDs
LPOPgives us an atomic,O(1)retrieval. One pop, one ID, sub-millisecond.
But a pool drains. I needed a way to refill it before it runs dry.
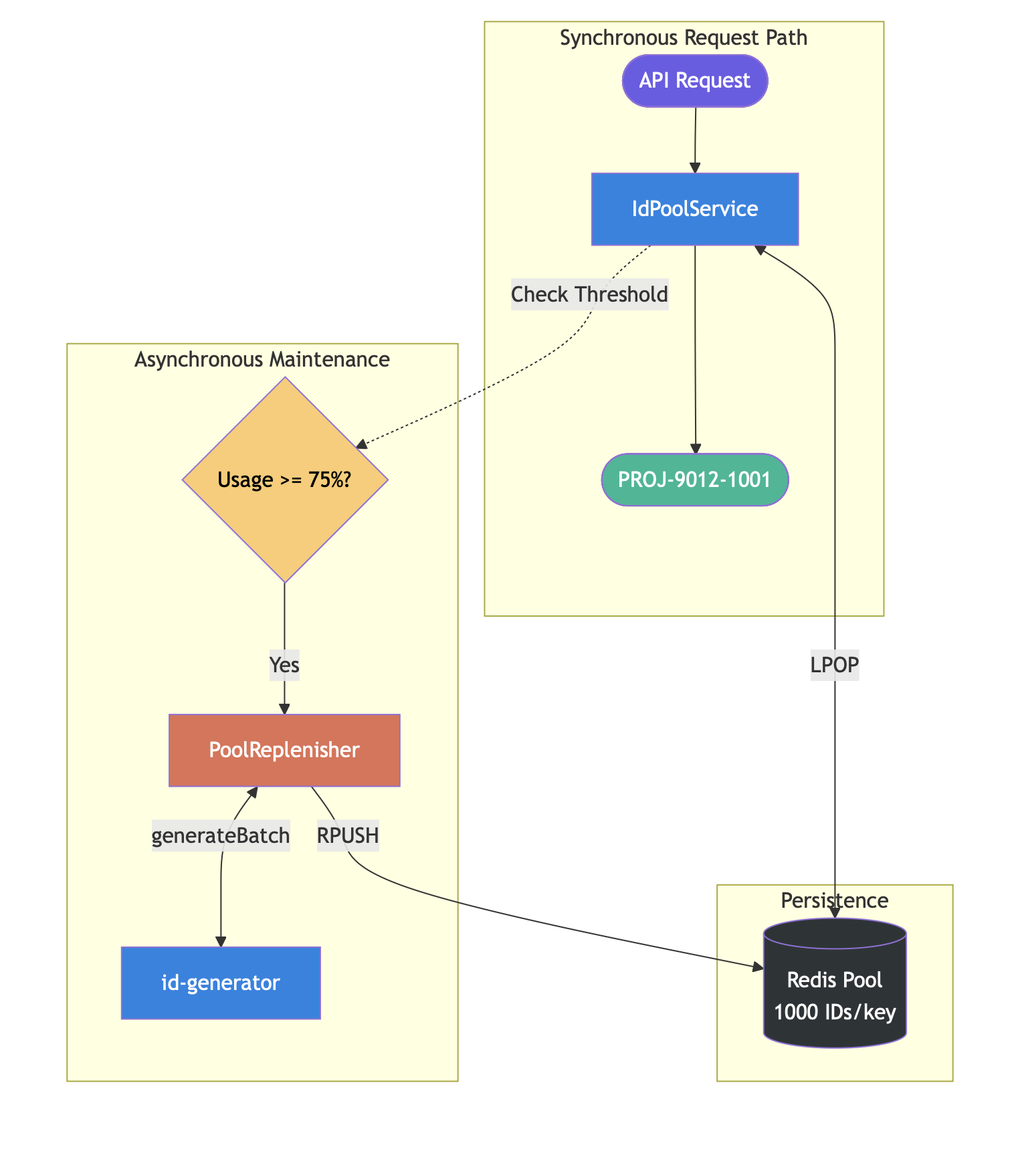
Threshold-based Replenishment
I used a watermark pattern, borrowed from stream processing systems like Kafka and Flink. You define a threshold level on a resource, and when usage crosses that mark, you trigger an action before the resource is exhausted.
Think of a water tank with a sensor at the 25% mark: when water drops below it, you automatically reorder before the tank runs dry.
In my case: each time an ID is served, I check the pool size. When 75% of the pool has been consumed (250 or fewer remaining out of 1000), I kick off an async task that calls the id-generator for a fresh batch and pushes them into the Redis list.
public String fetchNextId(String projectCode, String docTypeId) {
String poolKey = "id-pool:" + projectCode + ":" + docTypeId;
// Atomic pop - O(1), sub-ms
String sequence = redisTemplate.opsForList().leftPop(poolKey);
if (sequence == null) {
// Pool empty - synchronous fallback (discussed later)
sequence = idGenerator.generateSingle(projectCode, docTypeId);
}
checkAndReplenish(poolKey, projectCode, docTypeId);
return projectCode + "-" + docTypeId + "-" + sequence;
}
The replenishment runs on a bounded thread pool with CallerRunsPolicy. If the pool and queue are saturated, the request thread itself does the refill. This applies natural backpressure instead of silently dropping work. Or so I thought.
This worked beautifully in testing. Sub millisecond ID retrieval. Invisible background replenishment. We shipped it.
The Production Outage: OOM from a Thundering Herd
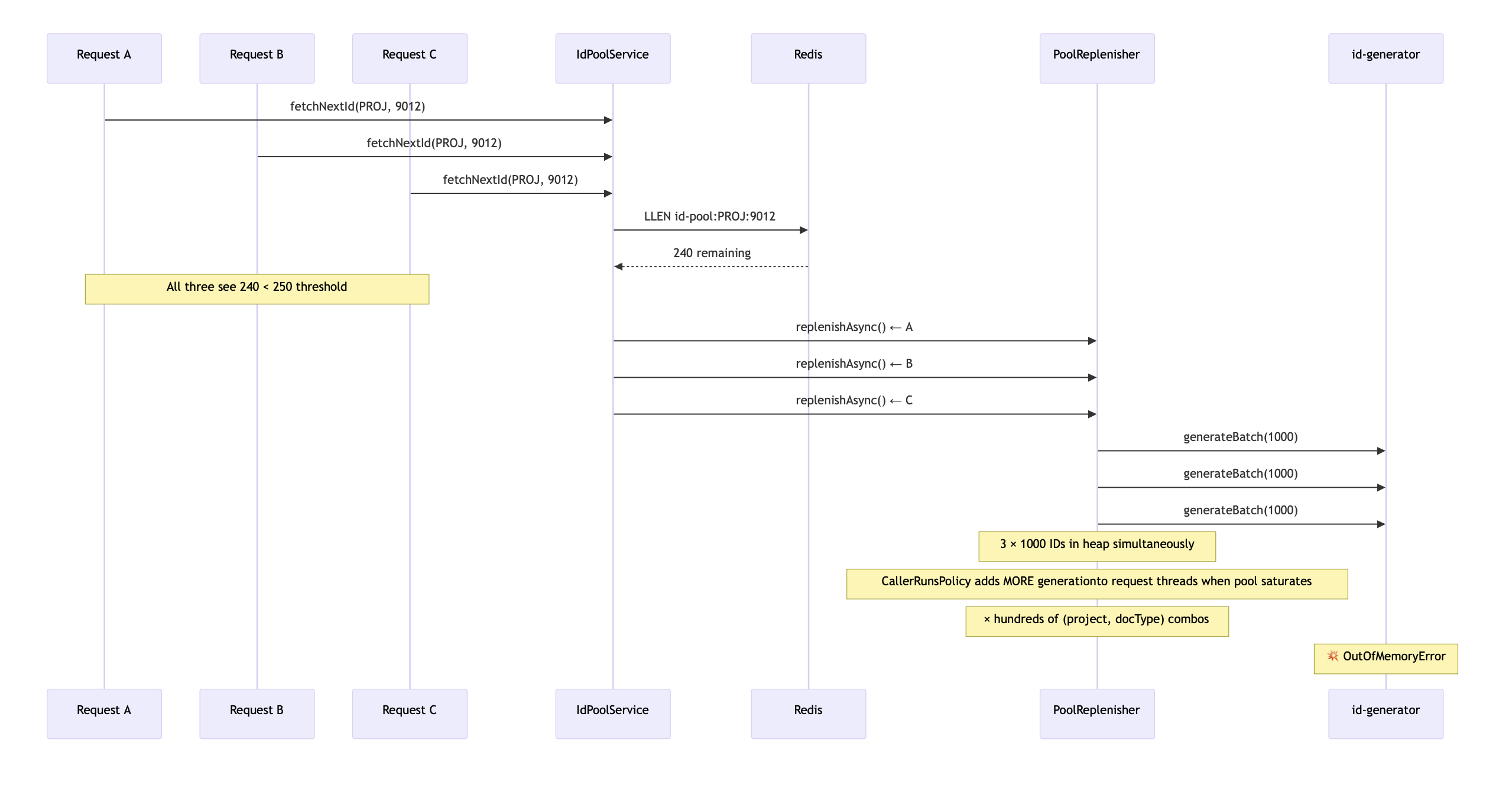
Within a week of going live with the large customer migration, the service started crashing with java.lang.OutOfMemoryError: Java heap space. Repeatedly.
I pulled a heap dump and started analysing it. The heap was full of hundreds of ArrayList<String> instances, each holding a thousand generated IDs. They were all alive simultaneously.
The root cause was a race condition in the replenishment logic.
Here’s what happened: during a bulk upload, thousands of concurrent requests hit the service. Multiple requests for the same (project, docType) would check the pool level at nearly the same instant, all see "below 75%", and all independently trigger replenishAsync(). Multiply this across hundreds of (project, docType) combinations, and you get hundreds of async tasks, each generating and holding a 1000 element list in memory.
The heap couldn’t take it.
Counterintuitively, the CallerRunsPolicy I'd chosen for backpressure made things worse. It was supposed to prevent RejectedExecutionException when the executor's queue filled up. It did by making the request-handling threads also run generation tasks, adding even more large lists to the heap. The policy solved thread pool rejection but amplified the memory problem.
The Fix: Redis Distributed Locks
The problem was clear: nothing prevented duplicate replenishment for the same pool key. I needed a mutex, but a Java ReentrantLock or synchronized block only protects a single JVM. Our service runs on multiple instances behind a load balancer. Instance A's lock means nothing to Instance B.
I needed a distributed lock. Redis gives you one with a single command:
SET lock:id-pool:PROJ:9012 "a1b2c3-uuid" NX EX 120
NX means "only set if it doesn't exist", atomic check-and-acquire. EX 120 means "auto-expire after 120 seconds", prevents deadlocks if the holder crashes.
##The Subtle Bug: Safe Lock Release
My first implementation used a simple DELETE in the finally block. This has a nasty race condition:
t=0s Instance A acquires lock (TTL=60s)
t=65s Lock auto-expires (A's generation was slow)
t=66s Instance B acquires the lock
t=70s Instance A finishes → DELETE → deletes B's lock
t=71s Instance C sees no lock → acquires → duplicate work
The fix: store a UUID as the lock value, and use a Lua script for atomic compare-and-delete. An instance only deletes the lock if the value still matches its own UUID.
Why Lua? Redis doesn’t offer a native "delete if value equals X" command. A GET followed by a conditional DELETE in application code has a race window another instance could acquire the lock between the GET and DELETE. Lua scripts execute atomically inside Redis, eliminating that gap.
@Async("idGenExecutor")
public void replenishAsync(String projectCode, String docTypeId) {
String lockKey = "lock:id-pool:" + projectCode + ":" + docTypeId;
String lockValue = UUID.randomUUID().toString();
// Atomic acquire: SET NX EX
Boolean acquired = redisTemplate.opsForValue()
.setIfAbsent(lockKey, lockValue, Duration.ofSeconds(120));
if (Boolean.FALSE.equals(acquired)) {
return; // Someone else is handling it
}
try {
// Double-check pool level under lock - another instance
// may have already refilled between our check and acquire
Long currentSize = redisTemplate.opsForList().size(poolKey);
if (currentSize > POOL_SIZE * 0.5) {
return; // Already refilled
}
List<String> newIds = idGenerator.generateBatch(
projectCode, docTypeId, POOL_SIZE - currentSize.intValue());
redisTemplate.opsForList().rightPushAll(poolKey, newIds);
} finally {
// Lua script: delete ONLY if value matches our UUID
String lua =
"if redis.call('get',KEYS[1]) == ARGV[1] then " +
" return redis.call('del',KEYS[1]) " +
"else return 0 end";
redisTemplate.execute(
new DefaultRedisScript<>(lua, Long.class),
List.of(lockKey), lockValue);
}
}
The double-check after acquiring the lock is the distributed equivalent of double-checked locking between the time I decided to replenish and the time I got the lock, another instance may have already done the work.
A note on Redisson’s RLock: it offers automatic lock renewal via a watchdog thread and reentrancy, which sounds appealing. I chose raw SET NX EX + Lua because my replenishment task has a predictable duration (200-500ms) a 120-second TTL gives 200x headroom. If generation ever takes longer than that, something is seriously wrong with the id-generator and I want the lock to expire. Adding Redisson for a single lock pattern felt like pulling in a heavy dependency for a problem I didn't have.
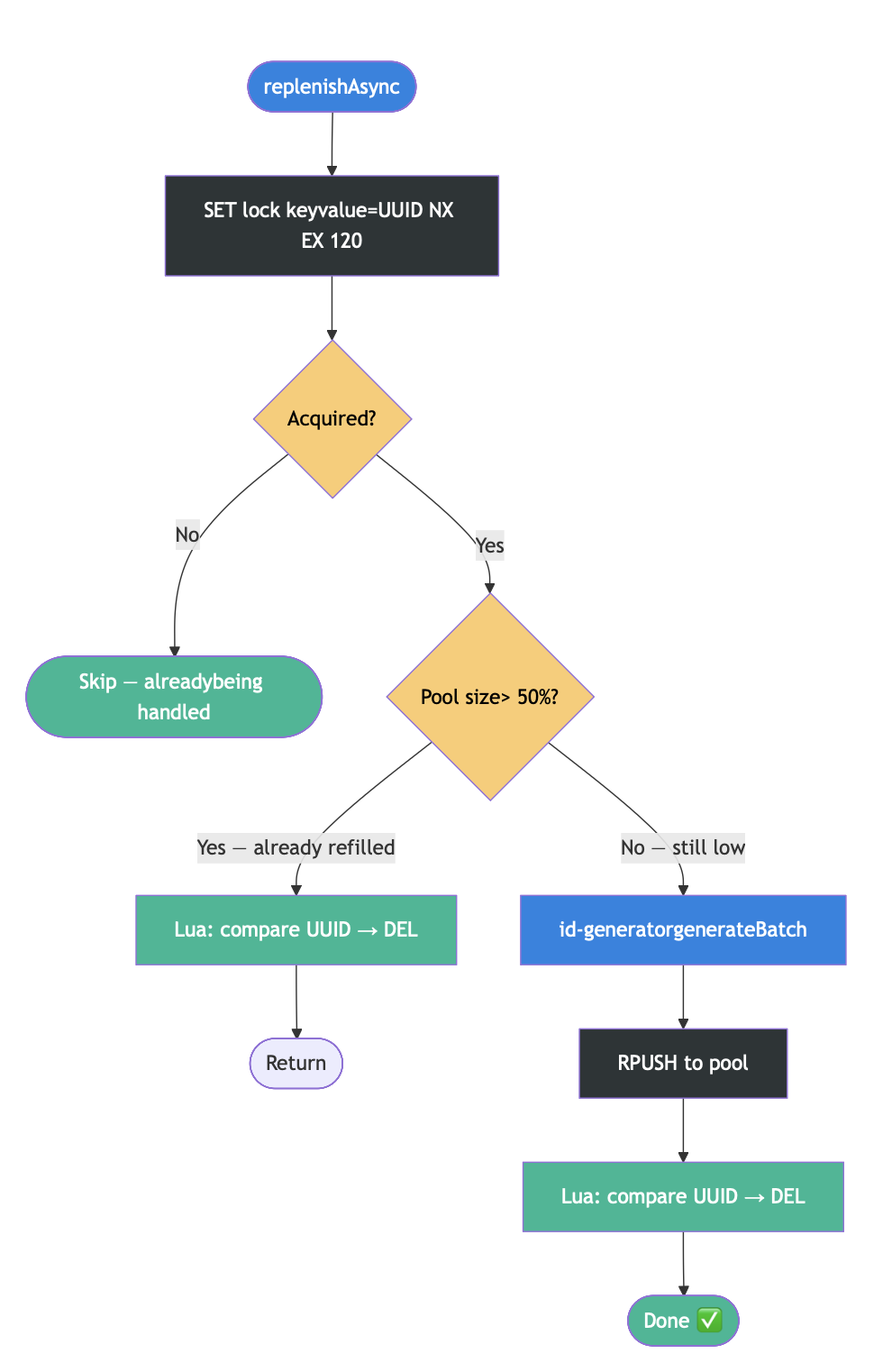
After this fix, OOM crashes dropped to zero. Each pool key gets exactly one concurrent replenishment, regardless of how many instances or threads are contending.
The Problem I Didn’t See Coming: Lost IDs
With performance solved, I hit a subtler issue during failure testing.
When a request pops an ID from the pool but the downstream document persistence fails network timeout, storage error, app exception that ID is gone. It was consumed from the pool, never attached to a document, and on retry the client gets a different ID. This creates sequence gaps and, worse, potential duplicates if the original write eventually succeeds after a timeout.
I considered several approaches: client-supplied idempotency keys (requires client cooperation unreliable with external API consumers), a reservation-commit pattern (extra Redis round-trips per request), and pre-assigned batch reservations (good for migrations, overkill for single uploads).
My Choice: The Outbox Pattern
I went with the Outbox pattern because it solves the problem entirely on the server side. No API contract changes. No client cooperation.
The idea: instead of popping an ID and then separately persisting the document, I pop the ID and write it along with the document metadata to an outbox table in a single database transaction. If the transaction fails, neither the ID assignment nor the record exists atomic.
A separate background processor handles the actual storage. The client gets their ID back immediately; the real persistence happens seconds later.
@Transactional
public String assignId(String projectCode, String docTypeId,
DocumentMetadata metadata) {
String docId = idPoolService.fetchNextId(projectCode, docTypeId);
// Single transaction: ID + record exist together or not at all
outboxRepository.save(OutboxEntry.builder()
.documentId(docId)
.tenantCode(projectCode)
.entityTypeId(docTypeId)
.payload(metadata)
.status(OutboxStatus.PENDING)
.retryCount(0)
.build());
return docId; // Client gets the ID immediately
}
The Outbox Processor: Retries, Backoff, and Dead Letters
The processor is a @Scheduled method that polls the outbox table every 2 seconds, picks up PENDING entries, and tries to persist each document to the target store.
On the happy path, it persists the document and marks the entry COMMITTED. But when storage fails with network timeout, S3 returning 500, disk full things get interesting.
A naive approach retries the entry on the next poll, 2 seconds later. If storage is down, I’m hammering it every 2 seconds and blocking the processor from making progress on other entries.
I used exponential backoff instead. Each outbox entry has a next_retry_at timestamp:
next_retry_at = NOW() + (2 ^ retry_count) seconds
Retry 1 waits 2 seconds. Retry 2 waits 4. Retry 3 waits 8. Retry 5 waits 32. Failing entries naturally “sink to the bottom” while fresh entries get processed promptly. The processor’s query becomes:
SELECT * FROM id_outbox
WHERE status = 'PENDING' AND next_retry_at <= NOW()
ORDER BY created_at LIMIT 100
After a maximum number of retries (I used 5), the entry moves to DEAD_LETTER status. This means the system has given up on automatic recovery and the document payload might be corrupted, the target storage bucket might not exist for this tenant, or there's a permission issue that no amount of retrying will fix.
Dead-lettered entries become a to-do list for the ops team: investigate, fix the root cause, and either reprocess manually or mark as abandoned.
Why not retry forever? A poisoned entry like corrupted payload, invalid schema will never succeed. Infinite retries waste processing capacity and mask the real bug. The dead letter queue acts as a circuit breaker for individual entries.
The outbox table:
CREATE TABLE id_outbox (
id BIGSERIAL PRIMARY KEY,
document_id VARCHAR(64) NOT NULL UNIQUE,
tenant_code VARCHAR(32) NOT NULL,
entity_type_id VARCHAR(32) NOT NULL,
payload JSONB NOT NULL,
status VARCHAR(16) NOT NULL DEFAULT 'PENDING',
retry_count INT NOT NULL DEFAULT 0,
next_retry_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
processed_at TIMESTAMPTZ
);
-- Partial index: only scans PENDING rows ready for processing
CREATE INDEX idx_outbox_pending
ON id_outbox (next_retry_at ASC) WHERE status = 'PENDING';
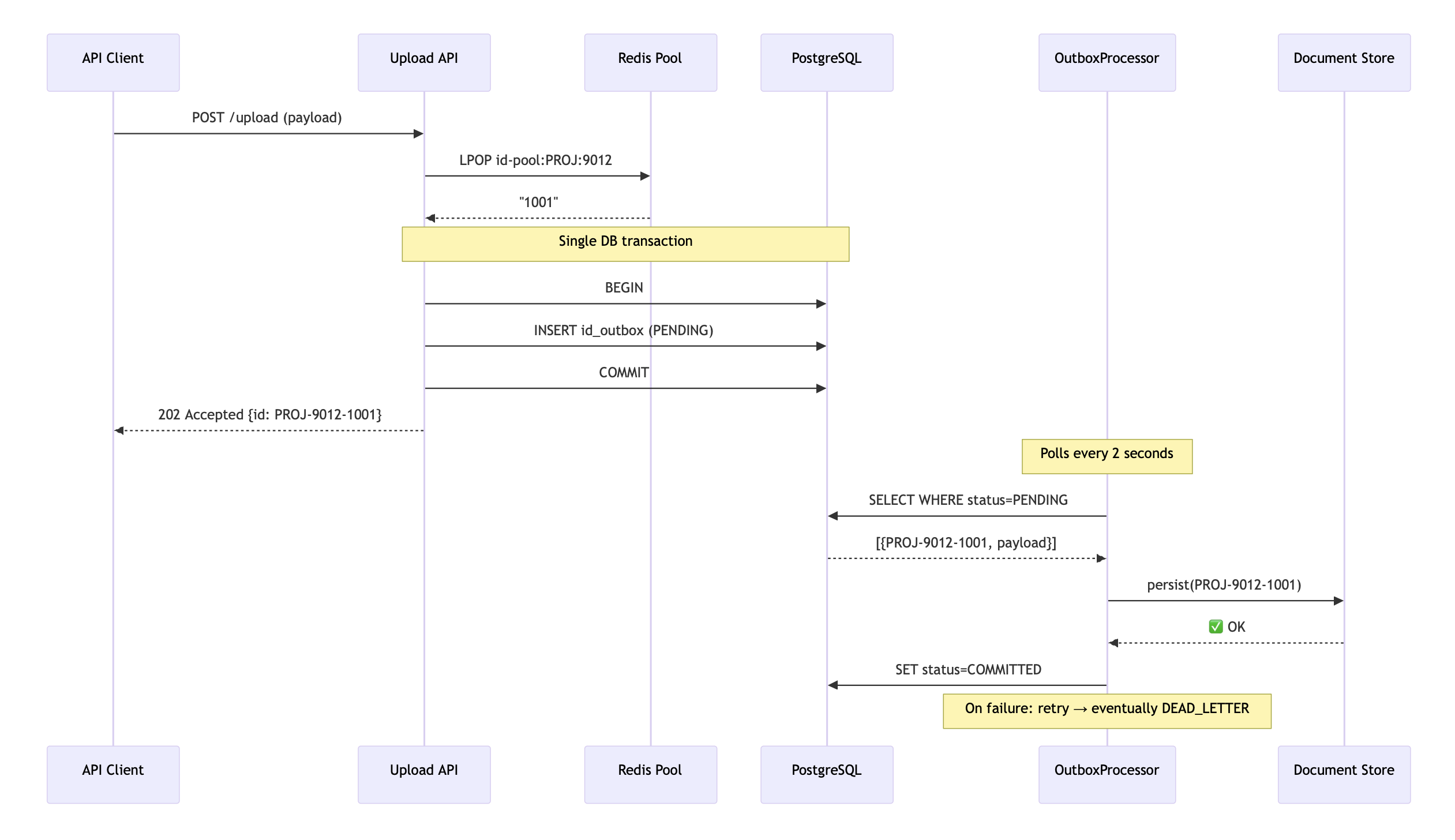
The tradeoff is eventual consistency. The document isn’t in the target store the instant the client gets the ID. There’s a 2–5 second delay while the processor runs. For bulk document uploads, this was perfectly acceptable.
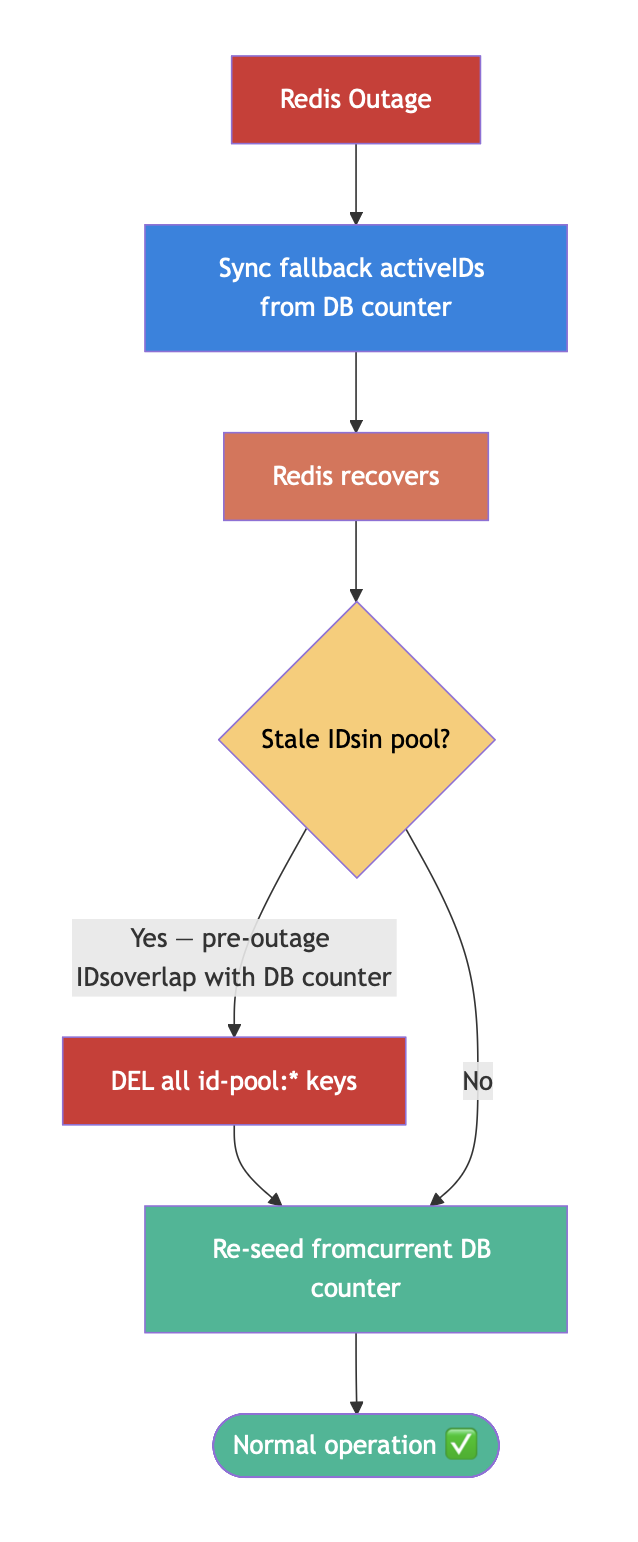
When Redis Goes Down
My fallback is straightforward: if LPOP fails with a RedisConnectionFailureException, fall through to synchronous id-generator calls.
try {
sequence = redisTemplate.opsForList().leftPop(poolKey);
} catch (RedisConnectionFailureException e) {
sequence = idGenerator.generateSingle(projectCode, docTypeId);
}
This re-introduces latency during a Redis outage (sub-ms jumps to ~200ms per ID), but the system stays available.
One important detail: the id-generator's sequence counter must live independently of Redis. If the generator also relies on Redis for its counter (INCRBY), then a Redis outage takes down both the pool and the fallback. I backed the counter with a database sequence so the fallback path has no Redis dependency.
The other concern is consistency after Redis recovers. During the outage, the sync fallback generates IDs using the database counter. The Redis pool still holds stale pre-generated IDs from before the crash. If you naively resume popping from the pool, you could issue duplicates.
My approach: on Redis reconnection, invalidate all pool keys and re-seed from the current database counter value. Simple but safe.
Results
Remember the back-of-envelope math? With the pool, a single ID retrieval drops from ~150ms (network hop to id-generator) to ~0.5ms (Redis LPOP). Across 3 app instances handling 20 concurrent requests each, the theoretical throughput for 200,000 documents is about 2 minutes. In practice, accounting for API gateway overhead, outbox commits, and occasional sync fallbacks, the observed results:

The gap between theoretical (2 min) and observed (~1 hour) is mainly the outbox processor’s polling interval, document storage latency, and the client’s own upload pacing. The 85% improvement is on the end-to-end migration, not just ID generation but ID generation was the bottleneck that unlocked everything else.
What I’d Improve
Gap Reconciliation
IDs still get lost. An instance can crash between popping from the pool and writing to the outbox. The outbox processor might exhaust retries and send entries to the dead letter queue. These are rare and a handful per million, but they create sequence gaps that confuse customers expecting contiguous numbering.
I’d address this with a periodic reconciliation job that compares three sources: the sequence counter (highest ID ever generated), the document table (which IDs have committed documents), and the outbox table (which IDs are still pending or dead-lettered). Everything in the counter range that doesn’t appear in any of these is a gap. The job writes these to a lightweight id_gaps table with the detection timestamp and inferred reason — outbox_dlq for dead-lettered entries, untracked_loss for IDs that never reached the outbox at all.
An endpoint like GET /api/v1/ids/gaps?project=PROJ&type=9012 would let customers distinguish "this ID was skipped due to infrastructure" from "this document is actually missing." Gaps become explained rather than mysterious.
I’d avoid trying to reclaim and reuse lost IDs. Reuse sounds clean but risks collision with late-arriving writes from the original assignment the kind of bug that’s nearly impossible to reproduce and debug. Better to waste a few numbers and track them than to reintroduce them into circulation.
Key Takeaways
-
Pre-populate, don’t generate on-the-fly. When generation is expensive or serial, trade storage for latency.
-
Watermark replenishment, not reactive. Refill at 75% consumed, not when empty. No request should ever wait on generation.
-
Distributed systems need distributed locks. Java’s
ReentrantLockdoesn't cross JVM boundaries. RedisSET NX EXgives you a lightweight mutex. -
Lock ownership matters. UUID lock values + Lua atomic compare-and-delete. Never blindly
DELETEa lock key. -
Double-check after acquiring the lock. The distributed equivalent of double-checked locking prevents redundant work.
-
Solve idempotency server-side. The Outbox pattern gives you atomicity without burdening API clients. Exponential backoff and dead letter queues turn “retry until it works” into something manageable.
-
Don’t reuse lost IDs. Track gaps, explain them, move on. Reuse introduces collision risks that are far worse than a missing number.
Originally published at chkrishnatej.dev
Comments
More Blog
View allgemmaFive Gemma-4 models, one accelerator: what porting E2B 31B to AWS Inferentia2 taught me
I ported the whole Gemma-4 family — E2B, E4B, 12B, 31B, and the 26B-A4B MoE — to run on...
X
xbillcommunityHey DEV, I'm Tobore. Let's actually connect.
Hey DEV, I'm Tobore. Let's actually connect. I've been on here for a while now, mostly writing and...
L
Laurina AyarahaiI burned through thousands of AI tokens. Then a friend did it for free
(yep, kinda clickbait, just for the funsies 😊) At the beginning of the year, I relaunched my...
P
Paulo HenriqueaiClaude might be saturating your machine
My laptop was sitting idle with the fan at full tilt. Nothing was running that I knew of. The culprit...
S
Sidhant PandagithubactionsAutomated GitHub Code Reviews Using Google Gemini
I Built a Thing! TL;DR — Google Gemini-based Pull Request reviews and Issue Triaging for...
D
Darren "Dazbo" LesteraiWhat is an "agentic harness," actually?
I've been hearing the word "harness" thrown around a lot lately. I assumed it just meant "the IDE" or...
T
Tilde A. ThuriumReady-made automations for this
Workflows from the Neura Market marketplace related to this DeepSeek resource
- End-to-End Blog Generation for WordPress with LLM Agents & Image - GP-5 Optimizedn8n · $24.99 · Related topic
- Customer Authentication for Chat Support with OpenAI and Redis Session Managementn8n · $14.99 · Related topic
- Automatic Google Cloud Run Auth with JWT Token Management (sub-workflow)n8n · $14.99 · Related topic
- PDF Document Filling and Generation Server for AI Agents with doqs.dev APIn8n · $14.99 · Related topic