Back to Blog analytics
analytics
 gemma
gemma community
community ai
ai ai
ai githubactions
githubactions ai
ai
Drizby: An Open Source BI Platform Built on a Semantic Layer (and why I built it)
Clifton Cunningham April 2, 2026
0 views
I've spent 20 years trying to answer one question: how do you give users analytics on their own data without building an entire BI platform? Turns out, eventually you just build the platform.
title: "Drizby: An Open Source BI Platform Built on a Semantic Layer (and why I built it)" published: true description: "I've spent 20 years trying to answer one question: how do you give users analytics on their own data without building an entire BI platform? Turns out, eventually you just build the platform." tags: analytics, opensource, typescript, ai cover_image: https://www.drizby.com/images/drizby_3.png
{kind=link}
Drizby: An Open Source BI Platform Built on a Semantic Layer (and why I built it)
For a large part of my career I've been building or buying analytics tools. At the DailyMail I built a real-time dashboard that helped grow traffic from 55M to 200M monthly uniques. At TES we built a data lake on Redshift with Looker powering self-service reporting across the entire business. At Infinitas we use Snowflake and PowerBI (which I will be glad to one day never use again).
Through all of that — and a lot of time with Metabase, Superset, Redash, Mixpanel, Amplitude — one question has kept coming back:
"How can I share self-service analytics with my customers in a scalable, secure and maintainable way?"
This is what led me to build drizzle-cube, an open source embeddable semantic layer for TypeScript apps built on top of Drizzle ORM. I wrote about that journey here. Drizzle-cube lets you define analytics cubes on top of your existing Drizzle schemas — measures, dimensions, time dimensions, security contexts — and expose them through a REST API that's compatible with the Cube.js query format.
But once I had the semantic layer working, I kept wanting more. I wanted dashboards. I wanted AI notebooks. I wanted a visual analysis builder. I wanted something I could point at a database and just use, without needing to embed it into an existing app first.
So I built Drizby.
What is Drizby?
Drizby is an open source BI platform — think Metabase or Superset, but built from the ground up on a semantic layer, with AI and embedding as first-class features. It's MIT licensed, ships as a single Docker container, and has no per-seat pricing.
docker run -p 3461:3461 -v drizby-data:/app/data ghcr.io/cliftonc/drizby:main
That's it. You get:
- Dashboards — drag-and-drop grid layout with 20+ chart types (bar, line, area, pie, scatter, KPI cards, treemaps, tables, and more)
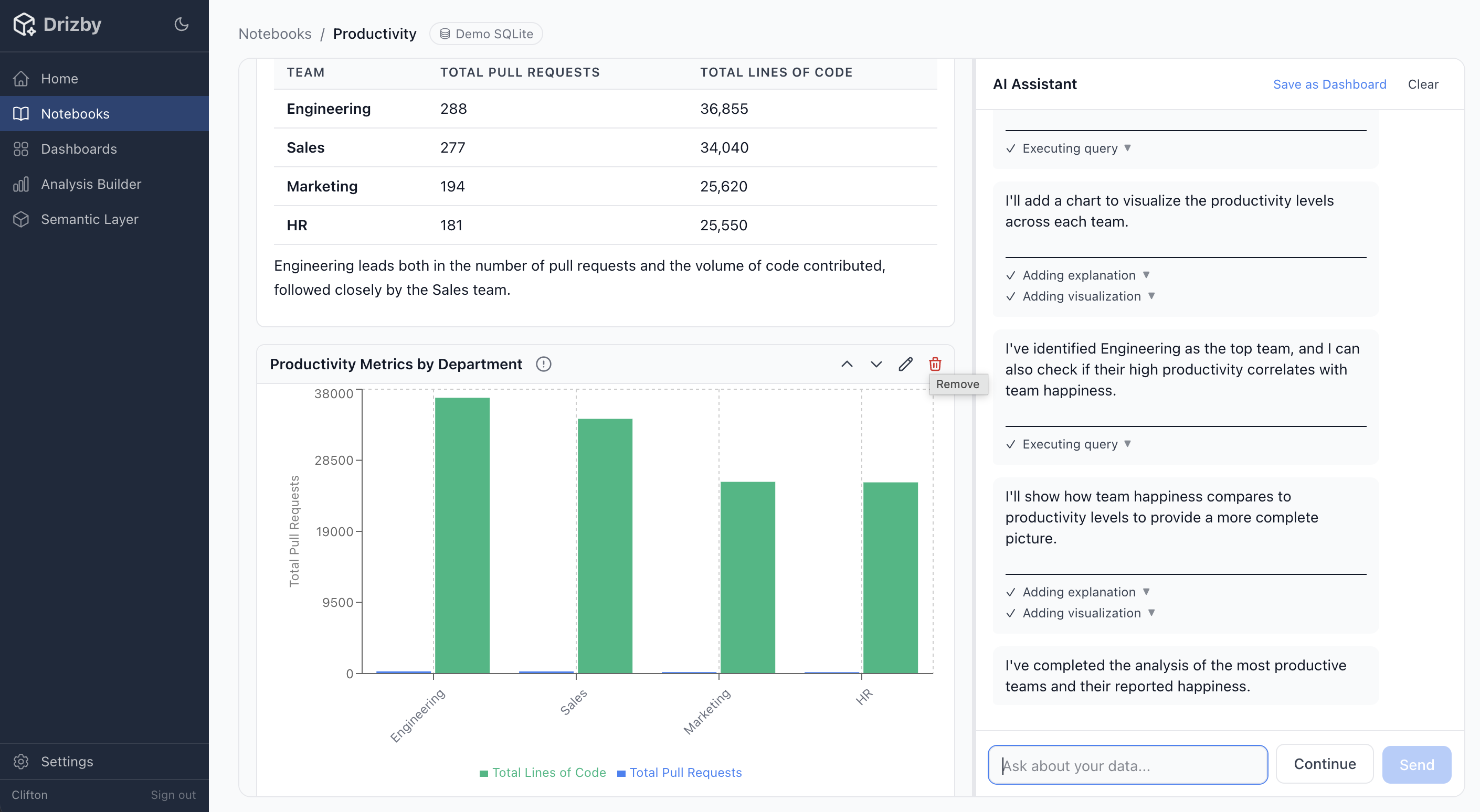
- Agentic AI Notebooks — multi-turn conversations with your data, where AI generates charts, tables and markdown insights in real time
- A Visual Analysis Builder — point-and-click query building inspired by Mixpanel and Amplitude, no SQL required
- A Schema & Cube Editor — Monaco editor with full TypeScript autocomplete for defining your semantic layer in code
- An MCP Server — expose your semantic layer to Claude, ChatGPT, Cursor, or any MCP-compatible AI assistant
- GitHub Integration — version control your entire semantic layer, tag releases, restore from any version
Why a Semantic Layer Matters
Most BI tools query your database directly. You write SQL or drag columns around, and the tool generates queries. This works until it doesn't — and it stops working the moment you need consistent metric definitions, multi-tenant security, or AI agents querying your data.
A semantic layer sits between your raw data and everything that consumes it. You define your metrics once — "revenue is sum of amount where status is completed" — and that definition is enforced everywhere. Dashboards, the analysis builder, AI notebooks, external API consumers, MCP-connected AI assistants: they all go through the same layer with the same definitions and the same security context.
In Drizby this is powered by drizzle-cube. If you already use Drizzle ORM, you're 80% done — your existing schema is the foundation. You define cubes on top of it:
const salesCube = createCube({
table: schema.sales,
dimensions: {
category: dimension(schema.sales.category),
orderDate: dimension(schema.sales.orderDate),
},
measures: {
totalRevenue: measure.sum(schema.sales.amount),
orderCount: measure.count(),
},
securityContext: {
organisationId: schema.sales.organisationId,
},
});
That securityContext line is important. Every query that runs through the semantic layer is automatically filtered by it. One customer can never see another customer's data. This isn't bolted on — it's baked into every query at the engine level.
Open Source at Its Core
This matters to me. I've used a lot of analytics tools over the years, and the pattern is always the same: you start free, you get locked in, and then the pricing conversation starts. Per-seat licensing in particular makes no sense in a world where AI agents and humans are querying the same data layer.
Drizby is MIT licensed. The semantic layer (drizzle-cube) is MIT licensed. You can self-host with unlimited users, unlimited dashboards, unlimited notebooks, unlimited connections. Your infrastructure, your data.
There is a Drizby Cloud option for people who don't want to manage infrastructure — usage-based pricing, no per-seat fees — but the self-hosted version is the same codebase with nothing held back.
Embedding as a First-Class Feature
This is where Drizby's lineage from drizzle-cube really shows. Because the entire platform is built on a semantic layer with a standard REST API, embedding analytics into your own app is straightforward.
You can use drizzle-cube directly if you want to embed analytics components into your existing React app — it gives you providers, hooks, and Tailwind-styled components for dashboards, charts, and the analysis builder. But you can also run Drizby as a standalone platform and consume its API, or connect AI assistants to it via MCP.
The MCP server is particularly interesting. You enable it in settings, and suddenly Claude Desktop, VS Code Copilot, or Cursor can discover your cubes, validate queries, and execute them — all with per-user OAuth 2.1 authentication and your security context enforced automatically. Your semantic layer becomes a set of tools that any AI agent can use.
From Database to Dashboards in Minutes
One of the things I'm most proud of is how automated the setup is. In most BI tools, connecting a database is just the start — then you spend hours or days modelling your data before anyone can build a dashboard. In Drizby the whole thing is AI-assisted and takes minutes.
Here's how it works:
1. Connect your database. Point Drizby at a PostgreSQL, MySQL, SQLite, or any Drizzle-supported database. It tests the connection and you're in.
2. Introspect the schema. Click "Introspect" and Drizby runs drizzle-kit pull under the hood to extract your full database schema as typed Drizzle ORM definitions. It post-processes the output — stripping exotic index types that generate invalid TypeScript, patching PostgreSQL array column annotations — so you get clean, compilable schema files. You then pick which tables you want to include.
3. AI plans your cubes. Once the schema is in, AI analyses your tables and proposes a set of analytics cubes. It identifies fact tables (orders, transactions, events) vs dimension tables (users, departments, products), skips junction tables and internal framework tables, and produces a plan. You get a checklist of proposed cubes — all pre-selected — and can deselect any you don't want.
4. AI generates the cubes. This is the fun part. Drizby streams the generation via SSE — you watch in real time as each cube is written, saved, and compiled. The AI maps your column types to the right dimension types (text→string, integer→number, timestamp→time), generates appropriate measures (count, sum, avg, min, max on numeric columns), and sets up the security context. Each cube is saved to the database and compiled immediately.
5. AI proposes joins. After the cubes are generated, AI analyses your foreign key relationships and naming conventions to propose joins between cubes — belongsTo, hasOne, hasMany, even belongsToMany through junction tables. Again, you get a checklist to review.
6. Joins are applied and everything compiles. The AI edits the cube source code to add the join definitions, recompiles everything, and registers the cubes with the semantic layer. Done.
From a fresh database connection to a fully queryable semantic layer with cubes, measures, dimensions and joins — typically under five minutes. You can see the whole flow in the getting started video.
At every step you have full control. The Monaco editor is right there with TypeScript autocomplete, so you can tweak anything the AI generated. But the point is you don't have to — the automated flow gets you to a working state fast, and you refine from there.
How It Compares
I've used most of the tools in this space, so here's my honest take:
vs Metabase — Metabase is great for getting started quickly, but it doesn't have a code-first semantic layer, AI notebooks, or an MCP server. Drizby adds these while keeping the simplicity of a single-container deployment.
vs Apache Superset — Superset is powerful but heavy. It requires a more complex deployment, doesn't have AI notebooks or MCP, and its SQL-based approach to metrics doesn't give you the same consistency guarantees as a typed semantic layer.
vs Looker — Looker pioneered the semantic layer idea with LookML. Drizby takes the same philosophy but uses TypeScript and Drizzle ORM instead of a proprietary language, is fully open source, and includes AI capabilities that Looker doesn't have.
vs Hex / Sigma — These are excellent products, but they're closed source with per-seat pricing. If you want to self-host, own your data pipeline, and not worry about seat costs as your team (and AI agents) grow, Drizby is the alternative.
The AI Angle
I'm building Drizby in what I think of as an "agentic world". The old model of BI was: humans log in, build dashboards, share them. The new model adds AI agents into the mix — they need to query your data too, and they need consistent definitions and security just like human users do.
The agentic notebooks in Drizby let you have a conversation with your data. Ask a question in plain English, get charts and insights back, ask follow-up questions, and when you find something worth sharing, promote it directly into a dashboard. The AI queries go through the same semantic layer as everything else — same definitions, same security, same source of truth.
And because of MCP, your data doesn't just live inside Drizby. Any AI assistant that supports MCP can connect to your semantic layer and query it as part of a broader workflow. Your analytics cubes become tools in the AI's toolkit.
The Tech Stack
For those who care about what's under the hood:
| Layer | Technology |
|---|---|
| Backend | Hono (TypeScript) |
| Frontend | React 18, TanStack Query, Recharts, Tailwind |
| Semantic Layer | drizzle-cube |
| Code Editor | Monaco Editor |
| Dashboard Grid | react-grid-layout |
| Internal DB | SQLite |
| User Databases | PostgreSQL, MySQL, SQLite, Snowflake, SingleStore, DuckDB, and more |
| AI | Anthropic Claude, OpenAI, Google Gemini |
| Auth | Sessions, OAuth (Google, GitHub, GitLab, Microsoft, Slack), SAML 2.0, SCIM |
The whole thing ships as a single Docker container. No Redis, no Postgres dependency for the app itself, no complex orchestration. Connect it to your databases and go.
Try It
If any of this resonates — if you've been looking for an open source BI platform that takes the semantic layer seriously, that treats AI and embedding as core features rather than afterthoughts, and that doesn't charge you per seat — I'd love for you to give it a try.
docker run -p 3461:3461 -v drizby-data:/app/data ghcr.io/cliftonc/drizby:main
Or check out the code: github.com/cliftonc/drizby
The semantic layer underneath: drizzle-cube.dev
The live demo of drizzle-cube: try.drizzle-cube.dev
I'm actively developing this and looking for real-world users and feedback. If this might solve a problem for you, I'd be really happy to help where I can. Open an issue, start a discussion on GitHub, or just take it for a spin and let me know what you think.
Comments
More Blog
View allgemmaFive Gemma-4 models, one accelerator: what porting E2B 31B to AWS Inferentia2 taught me
I ported the whole Gemma-4 family — E2B, E4B, 12B, 31B, and the 26B-A4B MoE — to run on...
X
xbillcommunityHey DEV, I'm Tobore. Let's actually connect.
Hey DEV, I'm Tobore. Let's actually connect. I've been on here for a while now, mostly writing and...
L
Laurina AyarahaiI burned through thousands of AI tokens. Then a friend did it for free
(yep, kinda clickbait, just for the funsies 😊) At the beginning of the year, I relaunched my...
P
Paulo HenriqueaiClaude might be saturating your machine
My laptop was sitting idle with the fan at full tilt. Nothing was running that I knew of. The culprit...
S
Sidhant PandagithubactionsAutomated GitHub Code Reviews Using Google Gemini
I Built a Thing! TL;DR — Google Gemini-based Pull Request reviews and Issue Triaging for...
D
Darren "Dazbo" LesteraiWhat is an "agentic harness," actually?
I've been hearing the word "harness" thrown around a lot lately. I assumed it just meant "the IDE" or...
T
Tilde A. ThuriumReady-made automations for this
Workflows from the Neura Market marketplace related to this DeepSeek resource
- Multi-Platform Price Finder: Scraping Prices with Bright Data, Claude AI & Telegramn8n · $24.99 · Related topic
- Real-time Sales Pipeline Analytics with Bright Data, OpenAI, and Google Sheetsn8n · $14.99 · Related topic
- Send Google Analytics Data to AI to Analyze, Then Save Results in Baserown8n · $14.99 · Related topic
- Create a Google Analytics Data Report with AI and Send It to Email and Telegramn8n · $9.99 · Related topic