Back to Blog backend
backend gemma
gemma community
community ai
ai ai
ai githubactions
githubactions ai
ai
Let's separate the separation
shymi December 31, 2025
0 views
It was during the last days of 2025 when our team lead decided to take an extra day off and missed an...
It was during the last days of 2025 when our team lead decided to take an extra day off and missed an interesting meeting. After a recent restructure, one colleague moved out of the project, and 2 newcomers were added.
The topic seemed simple: how should we structure our new code. Architects agreed on a DDD separation with additional grouping of rest, core and repository sub-packages(it is a Spring Boot web project) for each domain. This led to an interesting discussion separated should those three layers should be.
During my ~10-ish years of professional career, the most commonly used approach has been having a DTO POJOs at the entrance/exit of the REST controllers which were transformed to an entity objects which corresponded to the structure of the data in the storage used(i.g. RDBMS). Some process exclusive POJOs might exist, but we won't mention them for sake of simplicity. The process would look something like this:
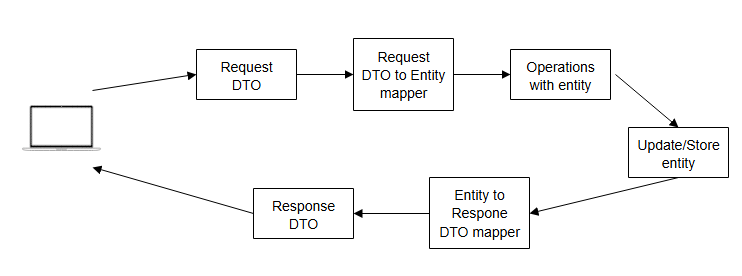
The main reason for separating the request/response objects from the ones which were used for storing/extracting data from a storage was that they might have a different structure and even if they are absolutely identical - it is a way to future-proof the code against changes.
Strictly speaking, this doesn't fully decouple the core and repository part of the code - any changes to the repository entity will directly affect the core, but in my experience you don't randomly change the entity you use without a need for that from the business logic(core) and thus I have formed the habit of only using a DTOs and entities.
There was a team decision, despite my disagreement, to fully decouple the core from the repository, so now we have something like this:
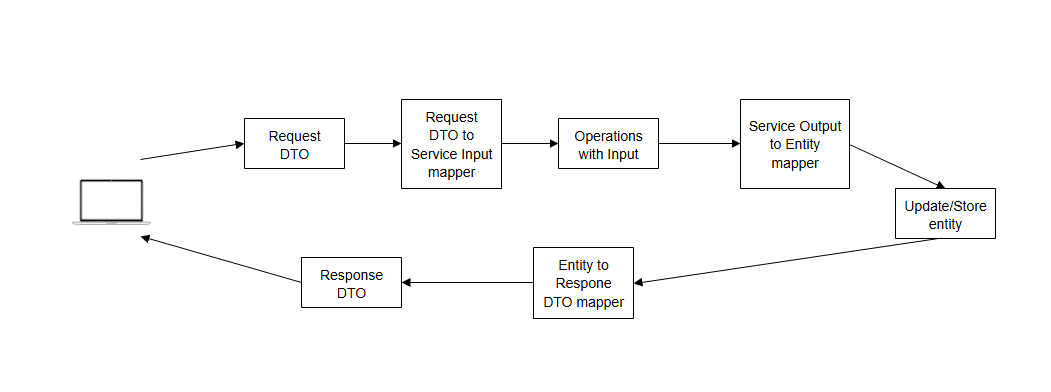
Although it seems pretty similar, now we have additional mappers and POJOs which are copies of the entities. My main concern was the overcomplication when a change is needed - there are more classes which must be changed, which, with time and project growth, will bring, in my eyes, unnecessary complication. At the meantime it might be useful in the future if there is an optimized structure for the process in the core classes which is totally different from the repository ones.
But hey - I might be wrong here and am afraid of a non-existent problem. Constructive feedback is always welcomed.
Godspeed and wish you all fantastic holidays!
Comments
More Blog
View allgemmaFive Gemma-4 models, one accelerator: what porting E2B 31B to AWS Inferentia2 taught me
I ported the whole Gemma-4 family — E2B, E4B, 12B, 31B, and the 26B-A4B MoE — to run on...
X
xbillcommunityHey DEV, I'm Tobore. Let's actually connect.
Hey DEV, I'm Tobore. Let's actually connect. I've been on here for a while now, mostly writing and...
L
Laurina AyarahaiI burned through thousands of AI tokens. Then a friend did it for free
(yep, kinda clickbait, just for the funsies 😊) At the beginning of the year, I relaunched my...
P
Paulo HenriqueaiClaude might be saturating your machine
My laptop was sitting idle with the fan at full tilt. Nothing was running that I knew of. The culprit...
S
Sidhant PandagithubactionsAutomated GitHub Code Reviews Using Google Gemini
I Built a Thing! TL;DR — Google Gemini-based Pull Request reviews and Issue Triaging for...
D
Darren "Dazbo" LesteraiWhat is an "agentic harness," actually?
I've been hearing the word "harness" thrown around a lot lately. I assumed it just meant "the IDE" or...
T
Tilde A. ThuriumReady-made automations for this
Workflows from the Neura Market marketplace related to this DeepSeek resource
- Automate Blog Content Creation with Notion MCP, DeepSeek AI, and WordPressn8n · $9.99 · Related topic
- Generate AI Videos from Scripts with DeepSeek, Synthesia, and Together.ain8n · $24.99 · Related topic
- Compare Multi-Period Financial Data from Google Sheets with DeepSeek AI Analysisn8n · $14.99 · Related topic
- Compose/Stitch Separate Images Together Using n8n & Gemini AI Image Editingn8n · $14.99 · Related topic