Back to Blog rag
rag gemma
gemma community
community ai
ai ai
ai githubactions
githubactions ai
ai
Implementing a RAG system: Crawl
Glen Yu March 23, 2026
0 views
I'm starting a "Crawl, walk, run" series of posts on various topics and decided to start with...
I'm starting a "Crawl, walk, run" series of posts on various topics and decided to start with Retrieval-Augmented Generation (RAG). Learn the basics and progress to a production-ready system!
Crawl
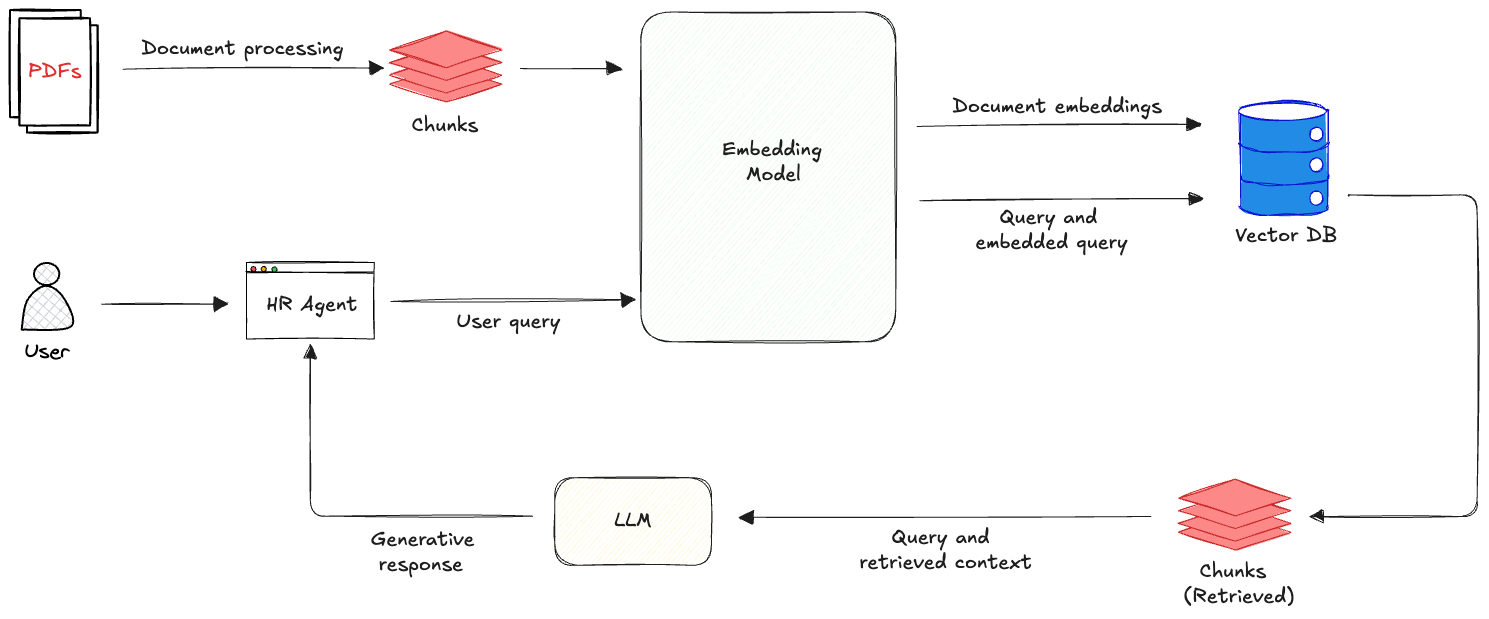
In this phase of your journey, we're going to learn about the core concepts of a Retrieval-Augmented Generation (RAG) system and then apply them in a simple example. We're going to build a Human Resources (HR) agent that can help answer and navigate HR-related questions. Using the Government of British Columbia's HR Policy PDFs as our knowledge base, we will process, chunk, and embed the documents into a local vector database. This allows the agent to provided grounded answers and ensures that every response is rooted directly in the ingested BC government policies.
Why RAG?
RAG is a very common design pattern that turns a standard LLM into an informed AI agent. Standard models can be a "black box", but RAG gives your agent an "open-book test". It bypasses knowledge cutoffs by linking directly to your documents, providing factual grounding and citations. No fine-tuning is required, data can be updated quickly. RAG provides a real-time bridge between your LLM and your data. This post will focus primarily on indexing and retrieval of the your data. Let's get started!
How do you eat an elephant? One bite at a time
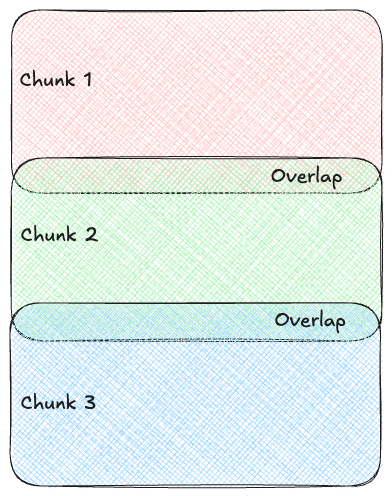
It's not feasible to have to feed all the information into the AI every time you want to ask it a question. Instead, it is broken down into smaller, more manageable pieces called chunks, which the AI can process and retrieve efficiently. We will use a "recursive character chunking" strategy which is a fast and smart and will try to split at natural boundaries like paragraphs, but can still cut off mid-sentence if the chunk is too big. An overlap is used to ensure that context isn't lost at the edges of a the cut if a split does occur.
Snippet of code used for splitting & chunking using LangChain:
from langchain_community.document_loaders import PyPDFLoader, DirectoryLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
loader = DirectoryLoader(
DATA_DIR,
glob="./**/*.pdf",
loader_cls=PyPDFLoader
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100
)
chunks = text_splitter.split_documents(docs)
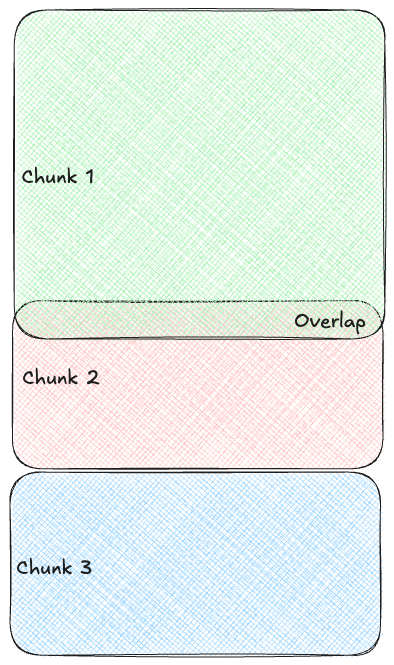
Recursive character chunking is the successor to "fixed-sized chunking", which is just a fixed sliding window. Here, you always need the overlap because you never know how much of what sentence you're cutting off.
What's the vector representation of 'Life'?
The embedding process transforms text chunks into vectors, which are mathematical arrays of floating-point numbers that capture semantic meaning. However, higher dimensionality won't necessarily generate better results. For simple or straightforward documents, expanding the vector size often introduces latency and computational overhead without providing better search accuracy.
Two sides of the same coin: Indexing & retrieval
Indexing and retrieval are two parts of the same conversation, and you must use the same embedding model for both. This is important because every embedding model puts emphasis on words in a sentence differently. One might prioritize the subject, while another might prioritize the action, which would yield different results.
What happens when different embedding models try to embed “To be, or not to be…”: {% embed https://www.youtube.com/watch?v=iQULEW2JwHE %}
Selection the appropriate embedding type is also very important. The documents that you embed and index are usually a long, structured documents where the focus is on the information it provides. This is in contrast to the user queries which are usually short, messy text, so the retrieval process focuses on the information it is looking for.
Finding a match
Once your user query is embedded, the RAG system performs a similarity search against the vector database to identify the most relevant answers. In most vector databases, this is calculated using cosine similarity. This metric focuses exclusively on the angle between vectors rather than their magnitude; it measures how closely the semantic "intent" (angle) of the query aligns with the document, regardless of the text's length or word frequency. This is important because it means the AI can recognize that a short question and a long technical manual can share the same intent even if their scale (magnitude) is completely different.
Putting it all together
Link to my GitHub repository → here
To handle HR questions, I'm building an agent using Google's Agent Development Kit (ADK) that connects directly to this RAG system:
from .tools import query_hr
hr_rag_tool = FunctionTool(func=query_hr)
hr_agent = LlmAgent(
name="hr_agent",
model="gemini-3.1-pro-preview",
description="Specialist in company HR policies and procedures.",
instruction=(
"You are a professional HR assistant. Your goal is to answer questions "
"using ONLY the information retrieved from the 'query_hr' tool. "
"When calling the 'query_hr' tool, ensure all string arguments are properly formatted as standard JSON strings with double quotes.\n\n"
"RULES:\n"
"1. If the tool returns relevant information, summarize it clearly.\n"
"2. You MUST cite your sources using the format: (Source: [Source Name], Page: [Page Number]).\n"
"3. If the tool results do not contain the answer, state: 'I'm sorry, I couldn't find that in our HR documents.'\n"
"4. Do not use outside knowledge or make up facts about company policy."
),
tools=[query_hr],
)
By giving the agent clear instructions and the right tools to search our vector database, it should be able to pull precise answers for users in seconds:
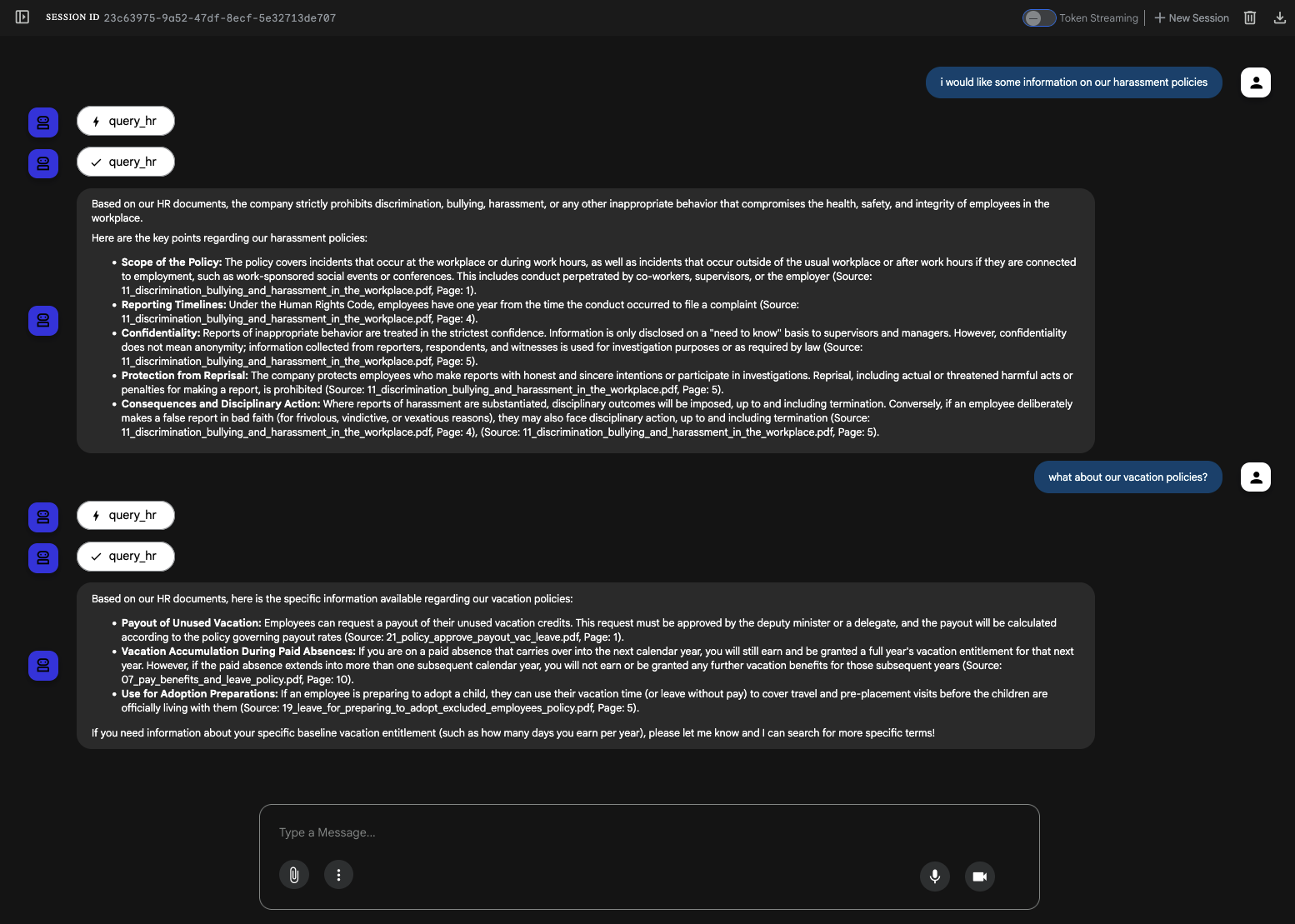
It answers questions reliably, but if I'm being honest, I can't help but feel we're only scratching the surface of the "full" answers that we're looking for.
Next steps
We have a working prototype, but there's still plenty of room to grow. To transform this from a simple RAG system into a high performance engine, our next steps will focus on precision. We'll refine how we process and chunk documents and introduce a reranking layer to our search results to significantly boost the quality of the agent's responses.
Additional learning
If you haven't used Agent Development Kit yet, but would like to learn more, checkout this Codelab: "ADK Crash Course - From Beginner to Expert" (it comes with a link to claim some free GCP credits to get you through the course).
Comments
More Blog
View allgemmaFive Gemma-4 models, one accelerator: what porting E2B 31B to AWS Inferentia2 taught me
I ported the whole Gemma-4 family — E2B, E4B, 12B, 31B, and the 26B-A4B MoE — to run on...
X
xbillcommunityHey DEV, I'm Tobore. Let's actually connect.
Hey DEV, I'm Tobore. Let's actually connect. I've been on here for a while now, mostly writing and...
L
Laurina AyarahaiI burned through thousands of AI tokens. Then a friend did it for free
(yep, kinda clickbait, just for the funsies 😊) At the beginning of the year, I relaunched my...
P
Paulo HenriqueaiClaude might be saturating your machine
My laptop was sitting idle with the fan at full tilt. Nothing was running that I knew of. The culprit...
S
Sidhant PandagithubactionsAutomated GitHub Code Reviews Using Google Gemini
I Built a Thing! TL;DR — Google Gemini-based Pull Request reviews and Issue Triaging for...
D
Darren "Dazbo" LesteraiWhat is an "agentic harness," actually?
I've been hearing the word "harness" thrown around a lot lately. I assumed it just meant "the IDE" or...
T
Tilde A. ThuriumReady-made automations for this
Workflows from the Neura Market marketplace related to this DeepSeek resource
- Automate Blog Content Creation with Notion MCP, DeepSeek AI, and WordPressn8n · $9.99 · Related topic
- Automate Altcoin News to LinkedIn Posts with DeepSeek AI and Google Sheetsn8n · $14.99 · Related topic
- Write a WordPress Post with AI (Starting from a Few Keywords)n8n · $24.99 · Related topic
- Generate AI Videos from Scripts with DeepSeek, Synthesia, and Together.ain8n · $24.99 · Related topic