Back to Blog hermesagentchallenge
hermesagentchallenge ai
ai hermesagentchallenge
hermesagentchallenge midsommar
midsommar ai
ai devchallenge
devchallenge antigravity
antigravity
I Made My AI Models Argue, Then Let Hermes Be the Judge
Arqam Waheed May 29, 2026
0 views
A $0 multi-model decision agent: three LLMs debate, Hermes judges, and it learns who to trust.
---
title: "I Made My AI Models Argue, Then Let Hermes Be the Judge"
published: true
description: "A $0 multi-model decision agent: three LLMs debate, Hermes judges, and it learns who to trust."
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/u5tswrazjdxvdqbz4j7t.png
---
*This is a submission for the [Hermes Agent Challenge](https://dev.to/challenges/hermes-agent-2026-05-15): Build With Hermes Agent*
> **TL;DR** — Ask any judgment call and three different AI models argue it out, then Hermes hands down one verdict, a confidence score, and exactly why they split. Every verdict, dissent, and mind-changed-in-debate is written into Hermes' own memory, so the next question re-weights the jurors before they ever vote. The judging is a pure function over that memory: no memory, no weights, no verdict. Three models, one verdict, $0.
---
## What I Built
An LLM once talked me into the wrong database with total confidence. One smooth, authoritative answer. I shipped it. It cost me a weekend and a migration I'm still not over.
The villain here is **single-model overconfidence**: you get one polished reply, and the disagreement that should have warned you is invisible. You never see the other opinions, because you only asked one model.
**So I stopped trusting one model. I convened a jury.**
Council takes any judgment call ("Postgres or Mongo?", "is this PR safe to merge?", "is this clause risky?") and asks **three different models**, lets them disagree, then has Hermes deliver one verdict, a confidence score, and exactly *why* they split. Three models, one verdict, $0.
You ask a question. Council fans it out to three jurors (two free OpenRouter models from different families and one local model via Ollama), each takes a position with reasons. Then, if they disagree, a **second deliberation round** runs: each juror sees the others' answers and either holds or changes its mind, so the council *debates* instead of just voting once. Hermes then judges the deliberated opinions: a single verdict, a **confidence score** (high when they agree, low when they split 2-1), and a "why they disagreed" panel. Every verdict is remembered, a `council` skill learns which juror to trust for which kind of question, and the agent can even **propose its own** trust adjustments for you to approve.
*The whole product is one question box. Everything interesting happens behind it, and the rest of this post is mostly pictures of that "behind."*
---
## Demo
{% youtube https://youtu.be/tREMaJuJGH4 %}
**Repo:** https://github.com/ArqamWaheed/council
**Live demo:** https://council-jet-kappa.vercel.app/
Hermes orchestration is local-only (no Hermes binary on serverless); the hosted demo runs the same UI via OpenRouter/mock. Run locally for the real hermes -z path.
Try "Should a 3-person startup use microservices?" and open the dissent panel.
Local, one command (runs at $0 in offline mock mode, no key needed):
```shell
git clone https://github.com/ArqamWaheed/council && cd council && ./setup_hermes.sh && python server.py
```
---
## Architecture, in pictures
I think the design is easiest to *see*, so here's the system as a sequence of images. Each caption is the explanation.
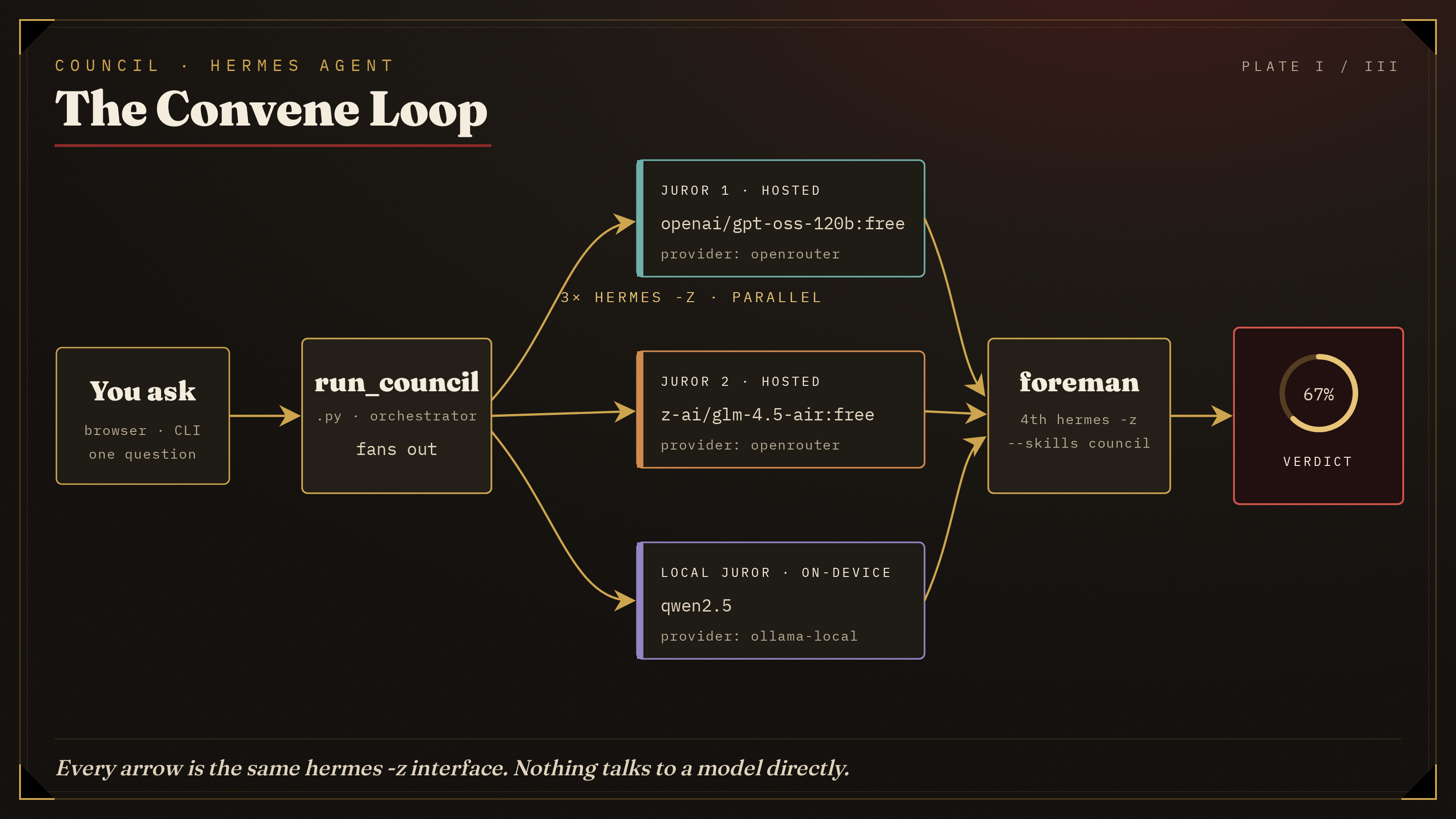
*The core loop. One question, three independent Hermes subagents (2 hosted + 1 local) fanned out in parallel, then a fourth Hermes run (the foreman) synthesizes one verdict. Every arrow is the same `hermes -z` interface; nothing talks to a model directly.*
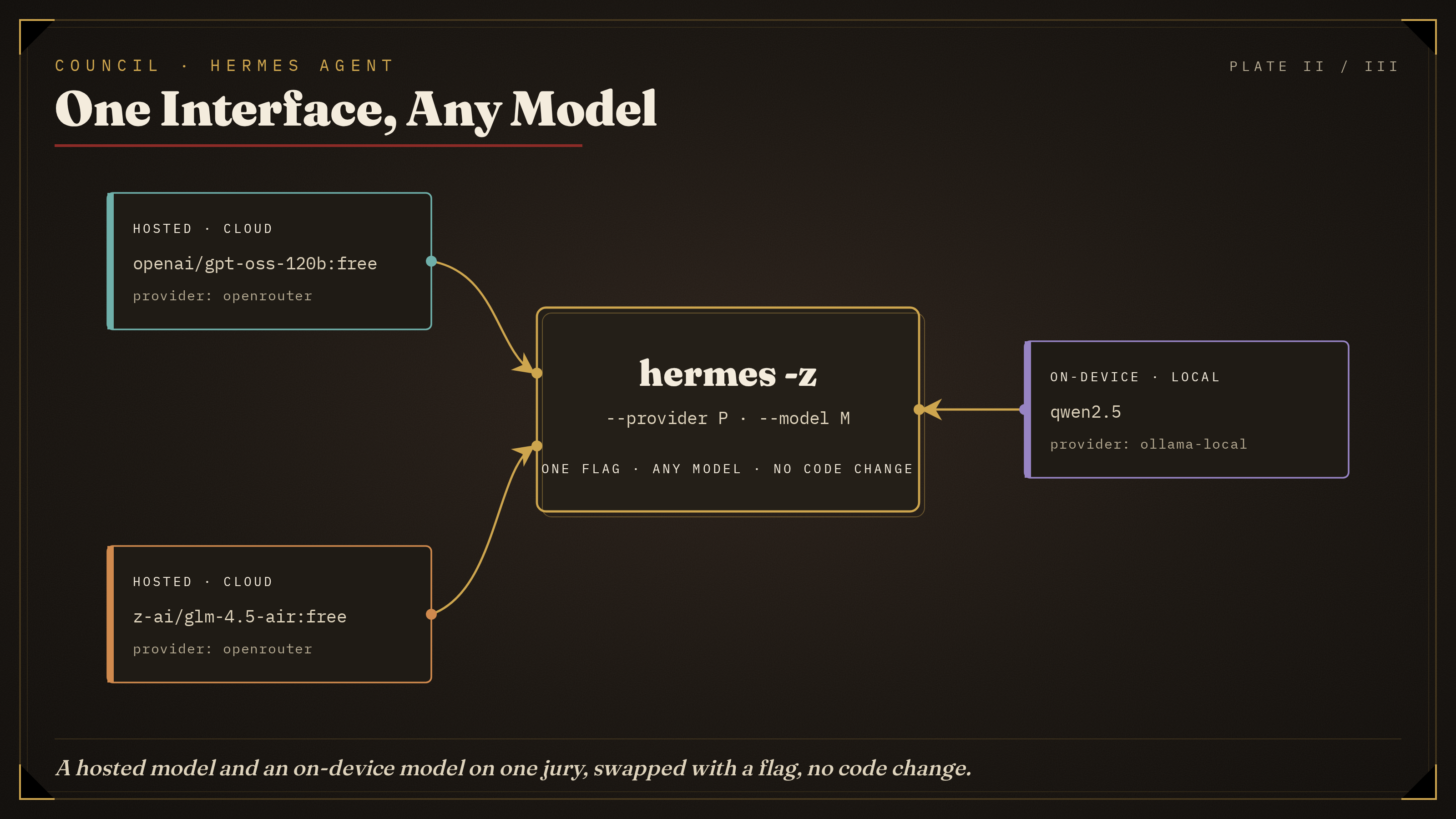
*The bet. A hosted model and an on-device model sit on the same jury, swapped with a single `--provider/--model` flag, no code change. This model-agnosticism is the one Hermes property the whole project is built on.*

*The UX surface. Confidence is high when jurors agree and drops on a 2-1 split. The dissent panel is collapsed by default, and you expand it exactly when the confidence number makes you nervous.*
![Dissent panel expanded: "Where they split" showing each dissenting juror, the option it endorsed, and its one-line reason, making the 2-1 disagreement legible at a glance]
(https://dev-to-uploads.s3.amazonaws.com/uploads/articles/cjyozmnkf3vfuu2fv2fp.png)
*The actual product. A confident single answer hides this; Council makes the disagreement the headline. Getting the clustering right here was subtle (see "What I learned" below).*
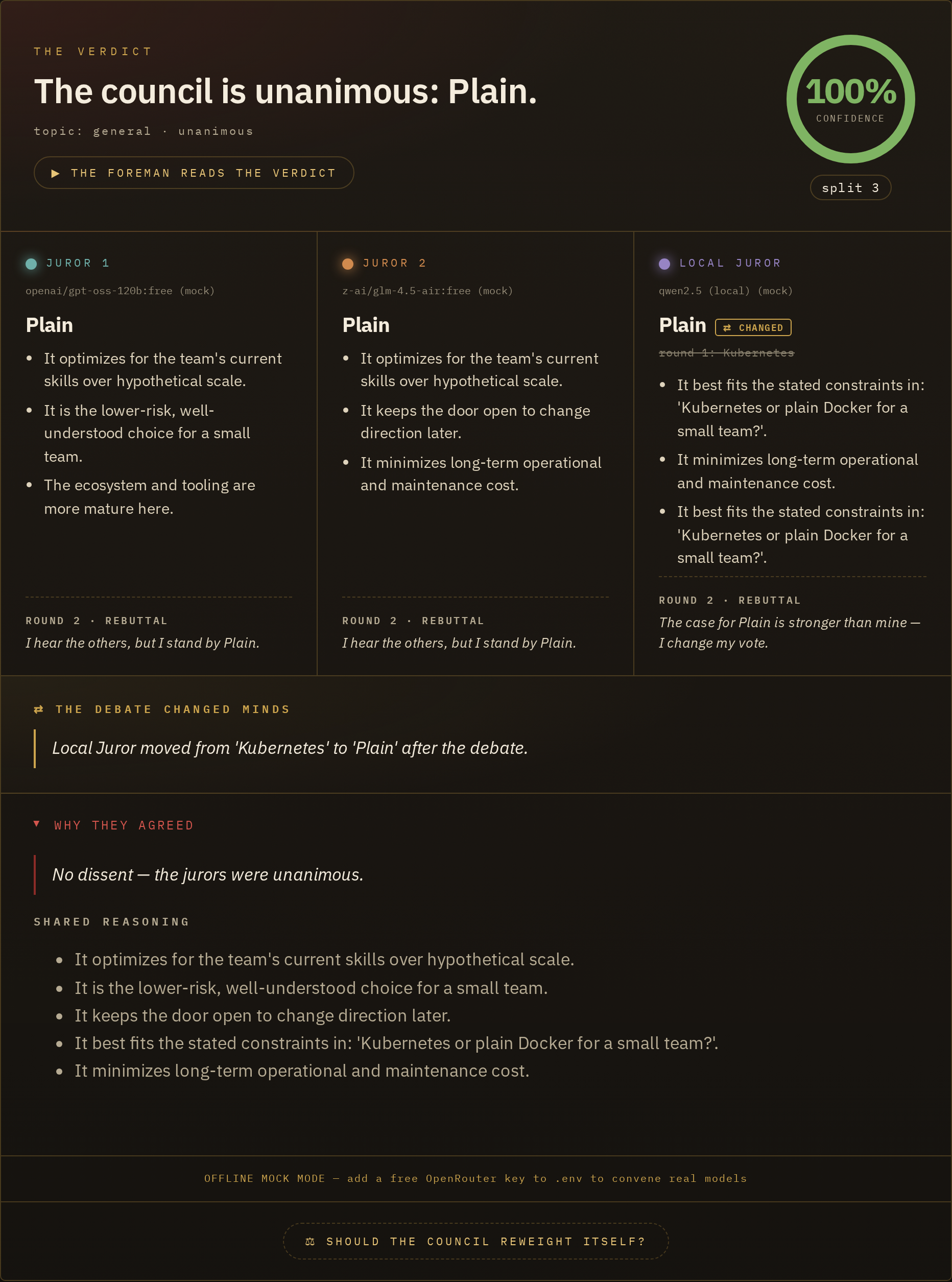
*The headline feature: a council that **deliberates, not just votes**. After round 1, disagreeing jurors get a second Hermes pass where they read each other's arguments and may hold or change their vote. A "⇄ changed" badge marks the ones that moved, and the confidence dial actually climbs when a 2-1 split is talked into agreement.*
![Reflect/approve flow: a "Should the council reweight itself?" button, Hermes reads the verdict history, returns a proposed weight rule card with Approve and Dismiss buttons, on Approve the rule is saved to browser localStorage and re-sent with the next question]
(https://dev-to-uploads.s3.amazonaws.com/uploads/articles/m81gxa5fsm8gvr6pz0iy.png)
*The agentic learning loop, human-in-the-loop. Hermes proposes; you approve or dismiss. Approved rules persist client-side and ride along with the next convene call.*
![Memory recall: a terminal running `hermes -z "what did the council decide about auth?"` and Hermes answering from its own MEMORY.md, not from project code]
(https://dev-to-uploads.s3.amazonaws.com/uploads/articles/jxozezam917mjgn1wcc1.png)
*Persistence the judge can verify. Verdicts are mirrored into Hermes' own memory, so recall is Hermes doing the work; proof lives in `docs/hermes-proof/04-memory-recall.txt`.*
---
## Code
**Repo:** https://github.com/ArqamWaheed/council
**Interesting files:**
* `hermes_run.py` (the Hermes CLI driver every juror/judge call goes through)
* `run_council.py` (orchestration + the deterministic judge + Hermes foreman + the `--reflect` loop)
* `skills/council/SKILL.md` (the juror-weighting brain Hermes edits)
* `server.py` (the `/api/reflect` + `/api/learn` endpoints)
* `index.html` (the designed verdict UI with the foreman TTS readout and localStorage persistence).
Proof that Hermes is genuinely in the loop (subagent transcripts, skill diff, memory recall) is in [`docs/hermes-proof/`](https://github.com/ArqamWaheed/council/tree/main/docs/hermes-proof).
```python
# hermes_run.py: every juror/judge call is a real Hermes run
def ask(prompt, provider, model, skills=None, timeout=120):
cmd = [binary(), "--provider", provider, "--model", model]
if skills: cmd += ["--skills", skills]
cmd += ["-z", prompt] # -z = one-shot, final answer on stdout
return subprocess.run(cmd, capture_output=True, text=True, timeout=timeout).stdout
# jurors.py: fan out one Hermes subagent per juror, in parallel
with ThreadPoolExecutor(max_workers=len(roster())) as pool:
opinions = list(pool.map(lambda c: ask_juror(*c), enumerate(roster())))
```
---
## How I Used Hermes Agent
**Why Hermes at all: the model-agnostic core.** Hermes lets you point at any provider and swap with a flag, no code change. Council is built *on top of that one property*: the jurors are different models, and Hermes is the only piece that makes "different models" cheap. The clearest proof is the third juror: it runs **locally** via Ollama while the other two are **hosted** on OpenRouter, and all three answer through the exact same `hermes -z` interface (the model-agnostic diagram above). A hosted model and an on-device model, sitting on the same jury, no code change: that's model-agnosticism you can see. I genuinely didn't see another entry in this challenge exploit it; everyone picked one model and moved on. That's the whole bet.
**Subagents: one real Hermes run per juror.** Each juror is a genuine, isolated Hermes invocation on a *different* provider+model (`hermes -z --provider openrouter --model …` for the two hosted jurors, `--provider ollama-local …` for the on-device one), fanned out **in parallel** so no model's reasoning anchors another's (the convene-flow diagram above). Hermes does the inference; my Python (`jurors.py` to `hermes_run.py`) is just the fan-out plumbing, and every juror in the output JSON is tagged `"via": "hermes"`. The gotcha worth flagging: Hermes enforces a **64K-context floor**, which for the local model meant setting both `ollama_num_ctx` *and* a named `custom_providers` entry; without the named provider, `--provider ollama` silently routed to the wrong base URL. `setup_hermes.sh` encodes the working config so a judge can reproduce it in one command.
**A true debate, not just a vote (round 2 is real Hermes work).** This is the feature I'm proudest of. After round 1, if the jurors disagree, each one gets a *second* Hermes run that shows it the others' positions and lead reasons and asks it to hold or change its mind. Real jurors reconsider through the same `hermes -z` path as round 1, so the debate is genuine extra agentic work, not a UI flourish; mock jurors reconsider deterministically so the offline demo stays reproducible. The judge then synthesizes the verdict from the **deliberated** opinions, so a juror that's talked round actually moves the outcome (the deliberation diagram above). It's gated on disagreement (a unanimous round 1 skips it) and toggled with `COUNCIL_DEBATE=0`.
**Why a skill, not a prompt, for judging.** The foreman's verdict is itself a Hermes run (`hermes -z --skills council`) grounded in `skills/council/SKILL.md`, which is **installed into Hermes** (`hermes skills list` shows it). The weighting logic lives in a machine-readable `weights` block.

*The judging brain is data, not a buried prompt. `--learn` and `--reflect` both edit this block, and the installed Hermes copy is kept in sync.*
After a string of security questions, `--learn` appended a rule to upweight the local model on that topic (*and synced the installed Hermes copy*) because it had caught issues the hosted models missed:
```shell
python run_council.py --learn "Local Juror | security | 1.5"
```
On the next security question that juror's vote counts 1.5×, read straight back by the judge. Counterfactual: a static synthesis prompt can't get better; this does. (The before/after skill diff is in [`docs/hermes-proof/03-skill-learning.txt`](https://github.com/ArqamWaheed/council/blob/main/docs/hermes-proof/03-skill-learning.txt).)
**Letting the agent propose its own learning, now on the web and grounded in evidence.** `python run_council.py --reflect` (and the **"Should the council reweight itself?"** button in the UI) hands Hermes its *own* memory of past verdicts and asks it to propose one weight change, e.g. "the local juror has dissented on three database calls; upweight it." The key fix this round: the proposal is **evidence-grounded**, since Hermes is fed the actual dissent tally and any rule backed by fewer than two real dissents is rejected, so it can't just parrot the example baked into the skill. You then **Approve or Dismiss** it (the reflect-flow diagram above). That's the agentic loop done honestly: a single verdict has no ground truth, so the agent surfaces a *pattern* and a human confirms it's signal, not overfitting (the exact tension this post closes on). (Offline, it falls back to a deterministic heuristic so it never breaks.)
**Making learning survive a stateless deploy.** On a hosted demo the filesystem is read-only, so an approved rule can't be written back to `SKILL.md`. Council handles this honestly: approved rules are stored in the browser's **localStorage** and re-sent with every `/api/convene` call, where they're merged into the judge's weights for that request. Locally you get a persistent `SKILL.md`; on the web you get per-browser persistence, and either way the learning sticks.
**Why memory.** Each verdict is appended to a log *and mirrored into Hermes' own `MEMORY.md`*, so I can ask `hermes -z "what did the council decide about auth?"` and Hermes recalls it from its memory, not from my code (the memory-recall image above). Proof: [`docs/hermes-proof/04-memory-recall.txt`](https://github.com/ArqamWaheed/council/blob/main/docs/hermes-proof/04-memory-recall.txt).
**The foreman reads the verdict aloud.** The verdict card has a "the foreman reads the verdict" button (browser SpeechSynthesis, $0); Hermes also ships native TTS via `hermes setup tts`. On-theme and memorable: a jury foreman *announcing* the decision.
**The build itself was agent-run.** I kept a `memory.md` the coding agent read before each task and updated after (so context stayed cheap), committed every increment with Conventional Commits, and built the verdict UI with the **frontend-design** skill, which is why the confidence dial and colour-coded juror chips read as *designed*, not default-template AI slop. The repo's `AGENTS.md` + commit history show the process, not just the result.
**Why these models, and the concession.** Two free OpenRouter models from different families (≥64K context, since Hermes rejects smaller at startup) plus a local Ollama juror. Two honest concessions: (1) free models are slower and three calls add latency (~10-20s/verdict); (2) the free tier is *aggressively* rate-limited, so I hit 429s constantly while building, and Council retries and, if a juror still won't answer, falls back (Hermes to direct API to deterministic stand-in) rather than crashing the verdict, which also means the demo runs **fully offline at $0**. For a once-a-decision tool, I'll take it. Cost: $0.
**License.** MIT. Fork it, add your own jurors.
---
## What I learned (and what's next)
- **The disagreement is the product.** A 2-1 split is *more* useful than a confident single answer, so the clustering that decides "who actually disagreed" has to be right. A small local model once wrote a vague position ("to facilitate efficient integration…") whose *reasons* clearly endorsed Postgres; the first version mis-filed it as a dissenter. The fix: when a juror's stated position is ambiguous, fall back to reading its reasons, and ignore options only mentioned in a comparison ("better *than* Mongo" isn't a vote for Mongo). Now agreeing jurors cluster together, and the split count is honest.
- **Grounded beats glib.** Letting the agent propose its own weighting only works if the proposal is tied to real evidence; an ungrounded "reflect" just echoes whatever example is in the skill.
- Hermes' 64K-context floor caught a model that would've quietly underperformed.
- **A council should deliberate, not just vote.** The round-2 debate above was the turning point: letting jurors read each other and reconsider means a juror that's genuinely persuaded moves the verdict, and you watch the confidence dial climb as a 2-1 split becomes unanimous. A one-shot vote can't do that.
---
Comments
More Blog
View allaiSkills over System Prompts: Building an Anki Tutor with the Antigravity SDK
AI has made me a little lazier. Not dramatically lazy. Not "the robots will do everything" lazy....
E
Ertuğrul DemirhermesagentchallengeCongrats to the Hermes Agent Challenge Winners!
We are thrilled to announce the winners of the Hermes Agent Challenge! Over the past few weeks, the...
J
Jess LeemidsommarFirebase Midsommer Madnesss with Antigravity CLI
This is a submission for the June Solstice Game Jam This installment brings a Firebase build to...
X
xbillaiI'm not a developer, but I built a calendar app to fix my most annoying work task
I’m not a developer! I’ve never coded anything in my life. As far as I’m concerned, a Cloudtop is...
A
Aria HellerdevchallengeCongrats to the Gemma 4 Challenge Winners!
We are so excited to announce the winners of the Gemma 4 Challenge! This is officially our most...
J
Jess LeeantigravityBuilding an agentic PR reviewer with Antigravity SDK
As announced in this blog post on June 18, 2026, Gemini CLI and Gemini Code Assist IDE extensions...
R
Remigiusz Samborski