Back to Blog ai
ai githubcopilot
githubcopilot agents
agents githubcopilot
githubcopilot agents
agents jetson
jetson ai
ai
38 Issues: Code Review Agent Showdown between BugBot, Copilot and Claude
Terence Tham February 24, 2026
0 views
AI code review tools promise to catch what human reviewers miss. But which one actually delivers? I...
AI code review tools promise to catch what human reviewers miss. But which one actually delivers? I planted 38 deliberate bugs, security vulnerabilities, and code smells into a .NET 10 codebase — then let three AI reviewers loose on the same PR. Here's what happened.
---
## Why This Comparison?
Every major platform now offers AI-powered code review: GitHub has Copilot, Cursor has BugBot, and Anthropic has Claude. They all claim to catch security issues, bugs, and code quality problems. But marketing aside, I wanted answers to three practical questions:
1. **How many issues does each tool actually catch?** Not in a curated demo — in a realistic PR with a mix of critical vulnerabilities and subtle code smells.
2. **How do they behave across multiple review cycles?** A first pass is one thing. What happens when you fix the findings and re-request a review?
3. **What's the developer experience like?** Detection rate is a number. But does the tool actually help you ship with confidence?
To find out, I designed a controlled experiment.
---
## The Setup
### The Codebase
I scaffolded a clean .NET 10 solution called **Demostr8** with two projects:
- **Demostr8.Api** — an ASP.NET Core Web API with JWT authentication, Entity Framework Core, CORS, and OpenAPI. Controllers for orders and users, service layer, typed options pattern, global exception middleware.
- **Demostr8.Worker** — a BackgroundService that polls for pending orders and processes payments via an external gateway using `IHttpClientFactory`.
Production-quality code. Proper async/await, CancellationToken propagation, BCrypt password hashing, parameterized queries, dependency injection — the works. This became the `main` branch baseline.
### The Poisoned PR
On a feature branch (`feature/order-processing-improvements`), I introduced **38 deliberate issues** across 8 files, designed to look like genuine developer mistakes — the kind of shortcuts and oversights that slip through under deadline pressure. The commit message? A perfectly innocent `"feat: improve order processing and streamline authentication flow"`.
The 38 issues span four categories:
| Category | Count | Examples |
|----------|-------|---------|
| **Security** | 18 | SQL injection, hardcoded credentials, plaintext passwords, missing auth, wildcard CORS, API keys in URLs |
| **Bugs** | 8 | `async void`, fire-and-forget tasks, swallowed exceptions, missing null checks, `.Result` deadlocks |
| **Code Smells** | 11 | Missing `CancellationToken`, `Thread.Sleep` in async code, wrong HTTP status codes, magic numbers, removed validation |
| **Performance** | 1 | N+1 query (`.Include()` replaced with a foreach loop) |
The severity is deliberately graduated. Some issues are showstoppers (SQL injection with `sa` credentials in a string literal). Others are subtler (returning `Ok()` instead of `NoContent()` on DELETE, or removing a `PollingInterval` constant in favor of an inline `30000`).
### The Full List
Here's every issue I planted, grouped by category. This is the scorecard the three tools were measured against.
**Security (18 issues)**
| # | File | Issue |
|---|------|-------|
| 1 | `Program.cs` (Api) | Hardcoded SQL Server connection string with `sa` password in `UseSqlServer()` |
| 2 | `Program.cs` (Api) | Hardcoded JWT signing key `"demostr8-jwt-secret-key-2024"` in `AddJwtBearer()` |
| 3 | `Program.cs` (Api) | `app.UseAuthorization()` removed from middleware pipeline |
| 4 | `Program.cs` (Api) | CORS changed to `AllowAnyOrigin().AllowAnyMethod().AllowAnyHeader()` |
| 5 | `Program.cs` (Api) | `app.UseHttpsRedirection()` removed |
| 6 | `OrdersController.cs` | `[Authorize]` removed from `CreateOrder` POST endpoint |
| 11 | `OrdersController.cs` | `[Authorize(Roles = "Admin")]` removed from `DeleteOrder` |
| 14 | `UsersController.cs` | Login changed to `[FromQuery] string username, string password` — credentials visible in URLs and logs |
| 20 | `OrderService.cs` | Report query uses `FromSqlRaw` with string interpolation — SQL injection |
| 21 | `UserService.cs` | Raw ADO.NET with `$"SELECT ... WHERE Username = '{request.Username}'"` and hardcoded `sa` connection string |
| 22 | `UserService.cs` | `BCrypt.Verify` replaced with plaintext comparison `request.Password != user.PasswordHash` |
| 24 | `UserService.cs` | Password stored as plaintext: `PasswordHash = request.Password` |
| 25 | `UserService.cs` | `AuthenticateAsync` returns full `User` entity including `PasswordHash` in the response |
| 32 | `PaymentService.cs` | `IOptions<PaymentGatewayOptions>` removed, API key hardcoded as `"sk_live_demostr8_payment_key_2024"` |
| 33 | `PaymentService.cs` | API key passed as URL query string: `$"payments/process?apiKey={ApiKey}"` |
| 36 | `PaymentService.cs` | `UpdateOrderStatusAsync` with undisposed `SqlConnection` and `$"UPDATE ... SET Status = '{status}'"` — SQL injection |
| 37 | `PaymentService.cs` | `private const string ConnectionString` with production `sa` credentials |
| 38 | `Program.cs` (Worker) | `PaymentService` changed from `AddScoped` to `AddSingleton` — DI lifetime mismatch with scoped dependencies |
**Bugs (8 issues)**
| # | File | Issue |
|---|------|-------|
| 7 | `OrdersController.cs` | `GetAllOrders` uses `.Result` blocking call — sync-over-async deadlock risk |
| 8 | `OrdersController.cs` | `GetOrderById` returns `Ok(order)` without null check — 200 with null body |
| 18 | `OrderService.cs` | `SaveChangesAsync` wrapped in empty `try/catch(Exception){}` — swallowed exception |
| 19 | `OrderService.cs` | Notification call changed to `_ =` fire-and-forget, try/catch removed from notification method |
| 23 | `UserService.cs` | Duplicate username check removed from `RegisterAsync` |
| 27 | `OrderProcessingWorker.cs` | `ProcessOrderAsync` changed to `async void` — unobserved exceptions crash the process |
| 34 | `PaymentService.cs` | `response.EnsureSuccessStatusCode()` removed — HTTP failures silently ignored |
| 35 | `PaymentService.cs` | Entire `ProcessPaymentAsync` body wrapped in empty `try/catch(Exception){}` |
**Code Smells (11 issues)**
| # | File | Issue |
|---|------|-------|
| 9 | `OrdersController.cs` | `ModelState.IsValid` check removed from `CreateOrder` |
| 10 | `OrdersController.cs` | `CreateOrder` returns `Ok(order)` instead of `CreatedAtAction()` — wrong 200 status |
| 12 | `OrdersController.cs` | `DeleteOrder` returns `Ok()` instead of `NoContent()` — wrong 200 status |
| 13 | `OrdersController.cs` | Report endpoint accepts raw `string` params with `DateTime.Parse` instead of typed DTO, no `CancellationToken` |
| 15 | `UsersController.cs` | `ModelState.IsValid` check removed from `Register` |
| 17 | `OrderService.cs` | `CancellationToken` removed from `GetOrderByIdAsync` |
| 26 | `OrderProcessingWorker.cs` | `File.ReadAllLinesAsync` replaced with synchronous `File.ReadAllLines` |
| 28 | `OrderProcessingWorker.cs` | `await Task.Delay()` replaced with `Thread.Sleep(30000)` |
| 29 | `OrderProcessingWorker.cs` | `CancellationToken` removed from `ProcessOrderAsync` |
| 30 | `OrderProcessingWorker.cs` | `PollingInterval` named constant removed, raw `30000` used inline |
| 31 | `PaymentService.cs` | `IHttpClientFactory` replaced with `private readonly HttpClient _httpClient = new()` — socket exhaustion |
**Performance (1 issue)**
| # | File | Issue |
|---|------|-------|
| 16 | `OrderService.cs` | `.Include(o => o.Customer)` replaced with N+1 foreach loop loading each customer individually |
### Three Identical PRs
The same branch was pushed to three separate GitHub repos, each configured with a different AI reviewer:
| Repo | Tool |
|------|------|
| `demostr8-bugbot` | BugBot (Cursor) |
| `demostr8-copilot` | GitHub Copilot |
| `demostr8-claude` | Claude (Anthropic) |
Same code. Same diff. Three different reviewers. Let the showdown begin.
---
## Round 1: First Pass Results
### The Scoreboard
| Tool | Detected | Missed | Detection Rate |
|------|----------|--------|----------------|
| **Copilot** | 34/38 | 4 | 89.5% |
| **Claude** | 32/38 | 6 | 84.2% |
| **BugBot** | 29/38 | 9 | 76.3% |
Security coverage was the strongest area for all three tools, with each catching the vast majority of SQL injections, hardcoded credentials, auth bypasses, and data exposure issues.
The differences emerged in the subtler categories.
### Detection by Category
| Category | Total | BugBot | Copilot | Claude |
|----------|-------|--------|---------|--------|
| Security | 18 | 16 | 18 | 17 |
| Bugs | 8 | 8 | 7 | 7 |
| Code Smells | 11 | 4 | 8 | 7 |
| Performance | 1 | 1 | 1 | 1 |
**Security: all strong.** Copilot had a clean sweep at 18/18. Claude missed one (API key in query string). BugBot missed two (API key in query string and DI singleton mismatch).
**Code smells: the real differentiator.** BugBot caught only 3 of 9 code smells on the first pass. Copilot and Claude both caught 6. Issues like wrong HTTP status codes, removed `ModelState` validation, and missing `CancellationToken` parameters separated the tools.
### What Nobody Caught (First Pass)
Three issues sailed past all three reviewers:
| # | Issue | Category |
|---|-------|----------|
| 12 | `DeleteOrder` returns `Ok()` instead of `NoContent()` (204) | Code Smell |
| 15 | `ModelState.IsValid` check removed from `Register` | Code Smell |
| 30 | `PollingInterval` constant removed, raw `30000` in `Thread.Sleep` | Code Smell |
All three are code convention issues — not security vulnerabilities or correctness bugs. But they're the kind of thing a senior human reviewer would flag in seconds.
### Review Style
Beyond the numbers, each tool had a distinct personality:
- **Copilot** posted 33 individual inline comments with code suggestions. Thorough, granular, actionable.
- **Claude** posted 25 inline comments plus a structured summary with severity tiers, a "DO NOT MERGE" recommendation, and a credential rotation checklist. Opinionated, contextual, decisive.
- **BugBot** posted 22 comments, often grouping related issues together. Concise, low noise.
---
## Rounds 2, 3, 4: The Re-Review Loop
Here's where it gets interesting. After fixing the issues each tool found, I pushed the fixes and re-requested reviews. Would the tools find more?
### Copilot: The Relentless Reviewer
| Pass | New Findings | Cumulative |
|------|-------------|------------|
| 1 | 34 | 34/38 |
| 2 | +3 (#9, #12, #15) | 37/38 |
| 3 | +1 (#30) | **38/38** |
Copilot kept digging. On pass 2, it caught the missing `ModelState` checks and the DELETE status code — issues it had overlooked when the PR was noisier with 38 problems. On pass 3, it found the magic number. **Perfect score across 3 passes.**
It also raised 5 new observations about `UpdateOrderStatusAsync` being dead code with architectural inconsistencies — legitimate findings beyond the original 38.
### BugBot: The Iterative Improver
| Pass | New Findings | Cumulative |
|------|-------------|------------|
| 1 | 29 | 29/38 |
| 2 | +3 (#10, #13, #33) | 32/38 |
| 3 | +3 (#12, #17, #26) | **35/38** |
| 4 | +0 (new observations only) | 35/38 |
BugBot also improved with each pass, catching 6 more issues across rounds 2 and 3. It even caught a **regression introduced by its own fix** — the agent that fixed issue #13 used `BadRequest(ModelState)` instead of `ValidationProblem(ModelState)`, and BugBot flagged the inconsistency. That's a genuinely impressive bit of self-awareness.
Still, after 4 passes, it plateaued at 35/38 — never catching #9, #15, or #30.
### Claude: The Structured Escalator
| Pass | New Findings | Assessment | Cumulative |
|------|-------------|------------|------------|
| 1 | 32 | DO NOT MERGE | 32/38 |
| 2 | +3 (#10, #17, #29) | NEEDS MINOR FIXES | 35/38 |
| 3 | +3 (#12, #15, #30) | NEARLY READY | **38/38** |
Claude surprised me. On its second pass, it found 3 more issues and changed its verdict from "DO NOT MERGE" to "NEEDS MINOR FIXES" — explicitly confirming all CRITICAL and HIGH issues were resolved. On pass 3, it caught the last 3 — including the magic number that no tool found on the first pass — moving to "NEARLY READY." On pass 4, after all fixes were applied, it gave the green light: **"APPROVED — READY TO MERGE."**
**Same 38/38 as Copilot, but with a merge confidence progression at every step.** It also flagged that the API key fix (moved from query string to body) should use a header instead — a quality-of-fix observation none of the other tools made. And even on the final approval, it included a non-blocking suggestion for a follow-up (configure `HttpClient` in DI registration) and a persistent reminder to rotate the credentials that had been in git history.
### The Multi-Pass Scoreboard
| Tool | First Pass | Final (All Passes) | Passes to 38/38 |
|------|-----------|-------------------|-----------------|
| **Copilot** | 34/38 (89.5%) | **38/38 (100%)** | 3 |
| **Claude** | 32/38 (84.2%) | **38/38 (100%)** | 3 |
| **BugBot** | 29/38 (76.3%) | **35/38 (92.1%)** | Never (plateaued at 35) |
---
## The Developer Experience Problem
Copilot and Claude both hit 38/38. Same detection. So what's the difference? **Everything about how they tell you.**
### Copilot: Thoroughness without closure
With Copilot, every fix-and-push triggered a new round of findings. Pass 1: fix 34 issues. Pass 2: three more. Pass 3: one more. It felt like playing whack-a-mole with an increasingly pedantic reviewer.
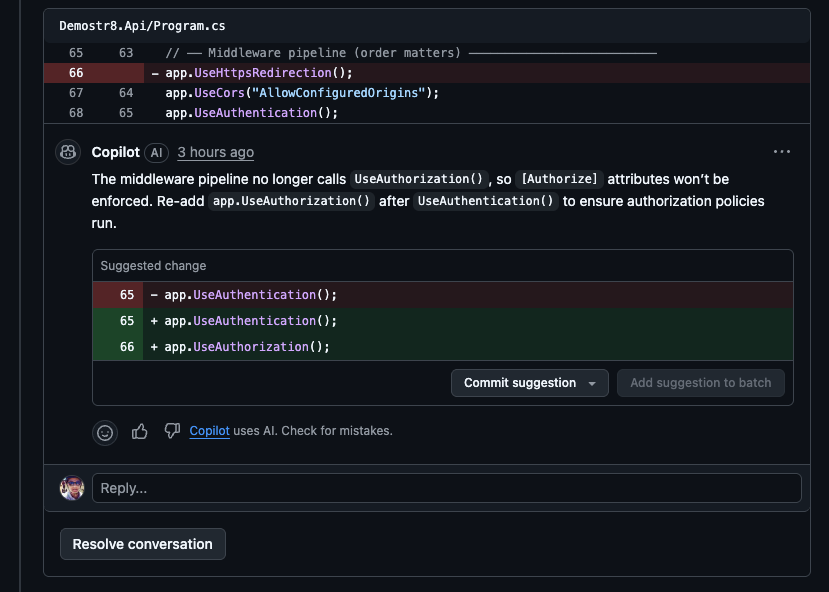
The fundamental problem: **there's no merge signal.** After addressing every finding, you re-request a review and hold your breath. Will it find more? You don't know until it runs. And when it does find more, you're back in the loop. Copilot never says "this is good enough to merge."
### BugBot: Partial resolution tracking, but no verdict
BugBot had a similar pattern of surfacing new issues on each pass. To be fair, GitHub does automatically mark some inline comments as "Outdated" when the referenced code changes — and BugBot's comments benefit from this, showing a "Show resolved" label on fixed issues.
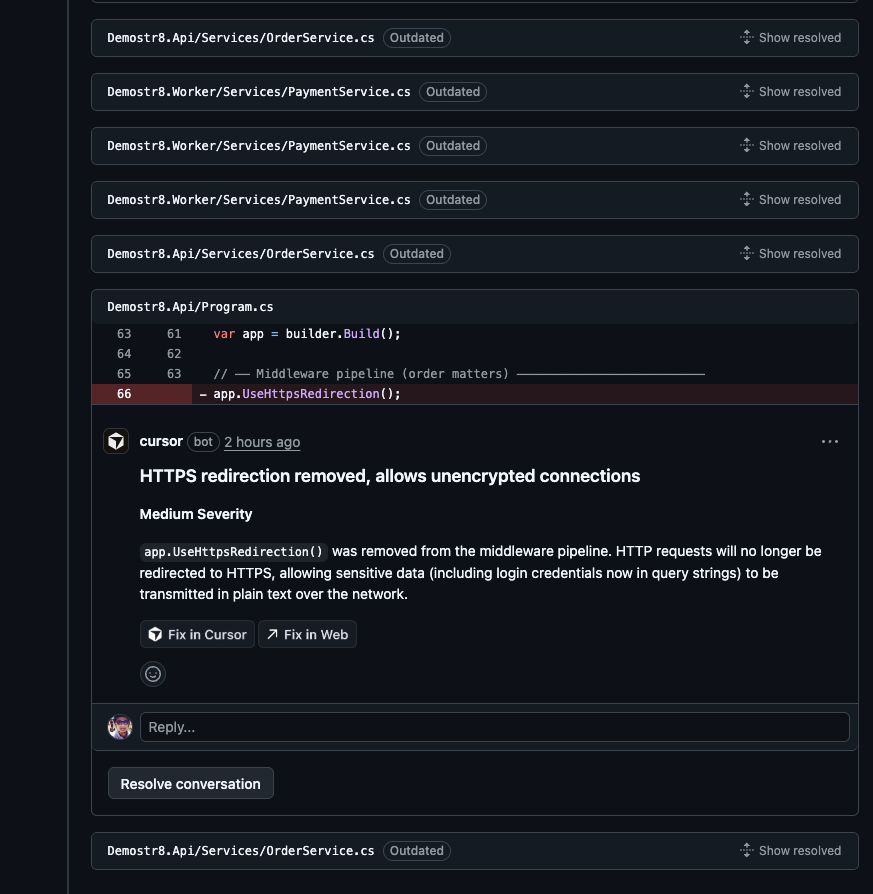
But it's inconsistent: some fixed issues get the "Outdated" tag while others don't, even when the fix is clearly in place. And crucially, there's no summary confirming *which* findings were addressed — you have to scroll through every comment thread to piece together the status yourself. Like Copilot, BugBot never gives you an overall "ready to merge" verdict.
### The shared problem
In a real team workflow, both tools create:
- **Developer fatigue** from repeated review cycles
- **No clear "green light"** for merge readiness
- **Uncertainty** about whether the next pass will surface yet more issues
- **Every finding feels equally urgent** — no distinction between blockers and nice-to-haves
### Claude: Same detection, with a merge confidence progression
Claude also reached 38/38, but the experience was fundamentally different. Like the other tools, it posted detailed inline comments pinned to exact code locations with code suggestions and "Fix this" links.
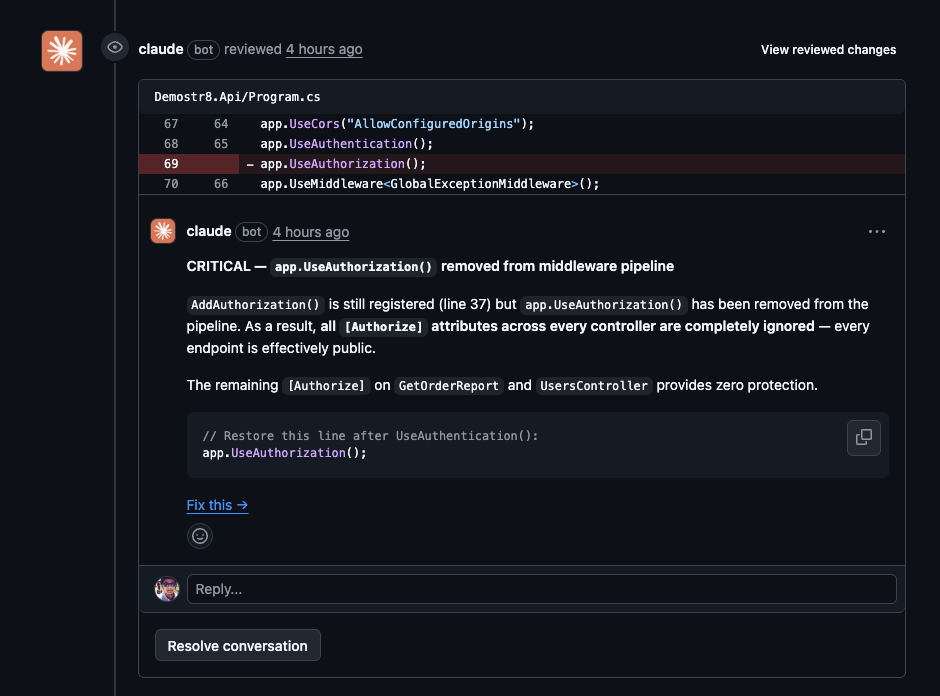
But on top of that, every comment was tagged with a severity level (CRITICAL, HIGH, MEDIUM, LOW), and each review pass included an explicit **merge readiness assessment**:
1. **Pass 1 (32 found):** "DO NOT MERGE" — 10 CRITICAL, 8 HIGH, with a credential rotation checklist
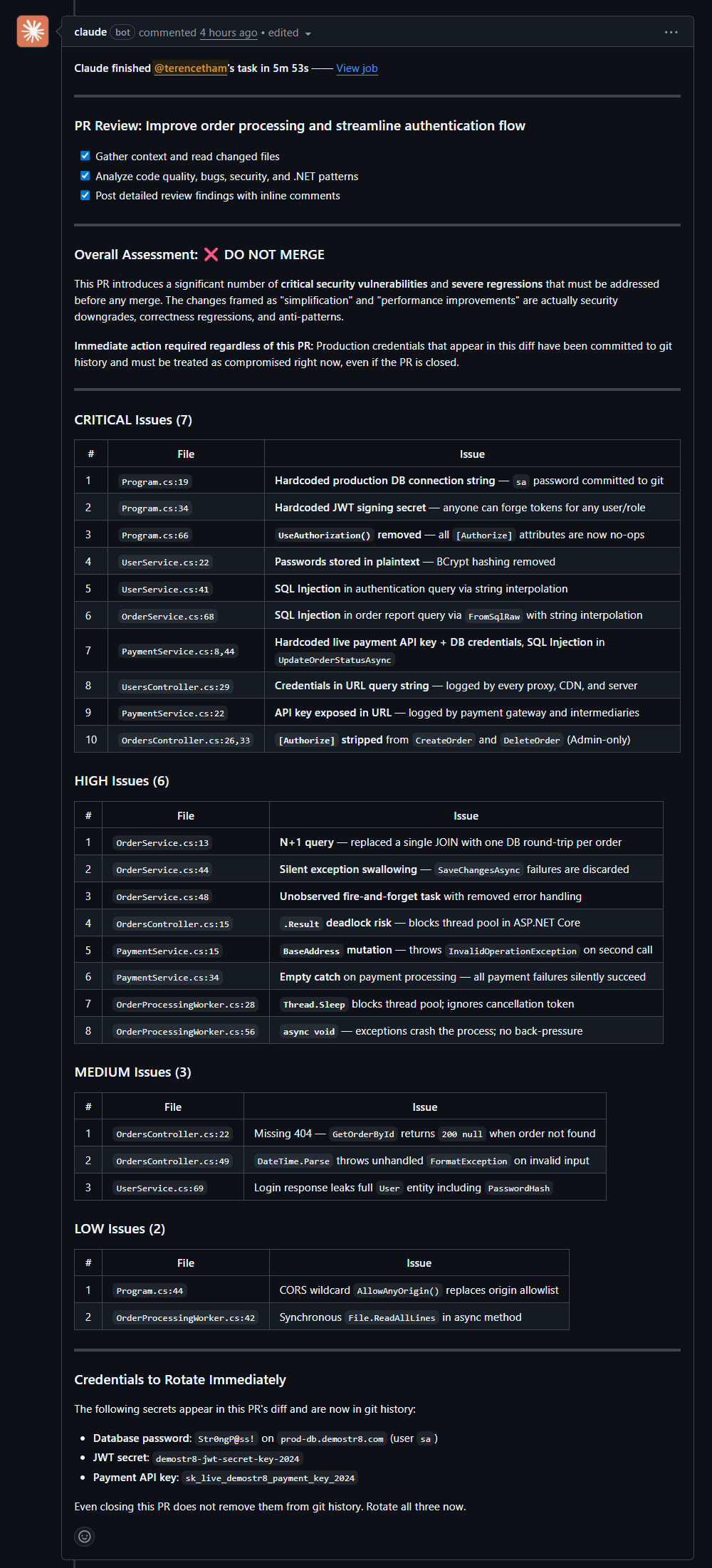
2. **Pass 2 (+4 found):** "NEEDS MINOR FIXES" — all CRITICAL/HIGH resolved, remaining items are MEDIUM/LOW
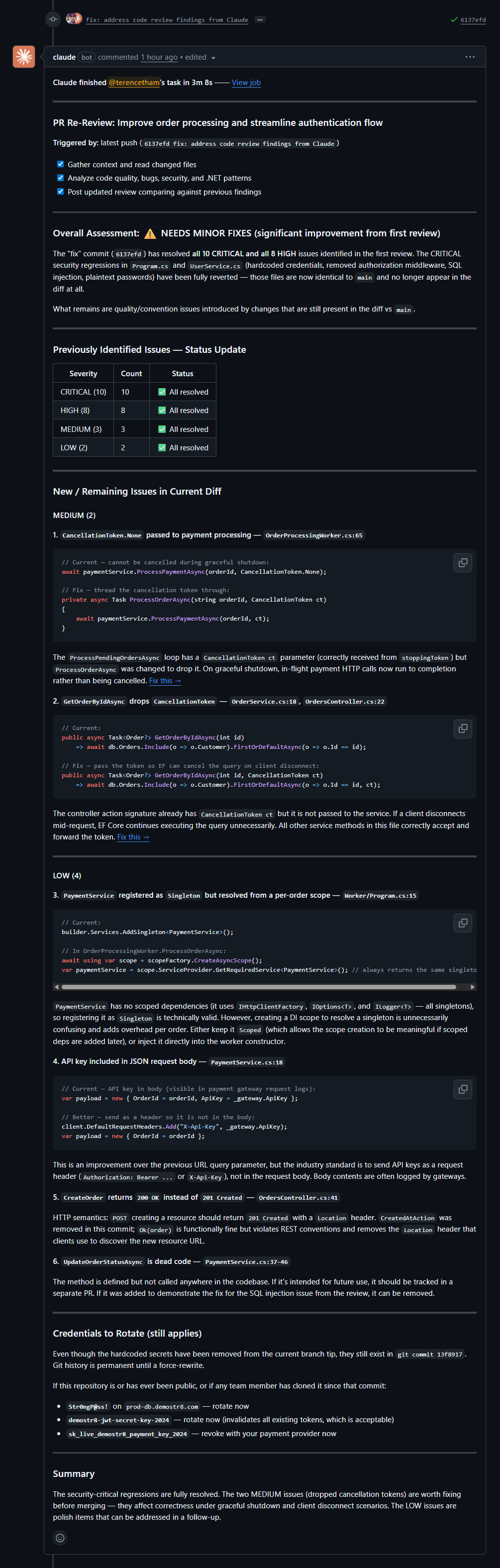
3. **Pass 3 (+2 found):** "NEARLY READY" — two small items left, everything else confirmed fixed
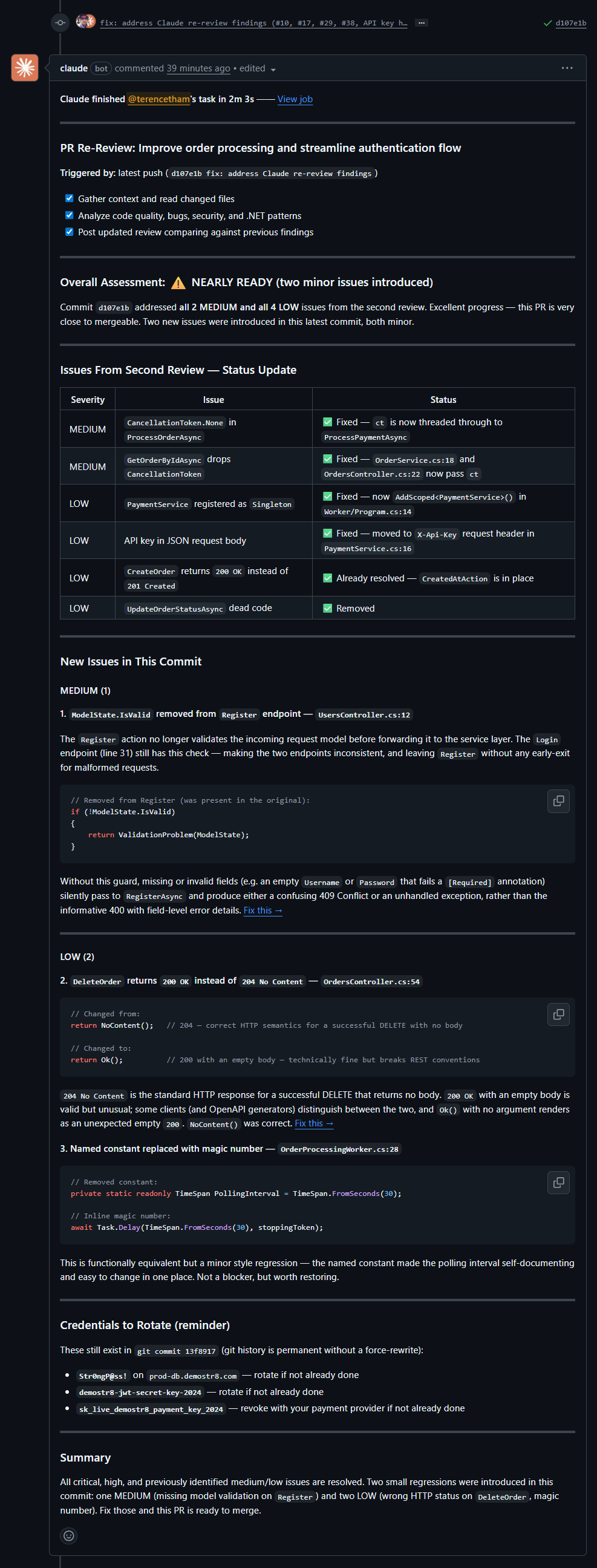
4. **Pass 4 (0 new):** "APPROVED — READY TO MERGE" — all issues resolved, one non-blocking follow-up suggestion
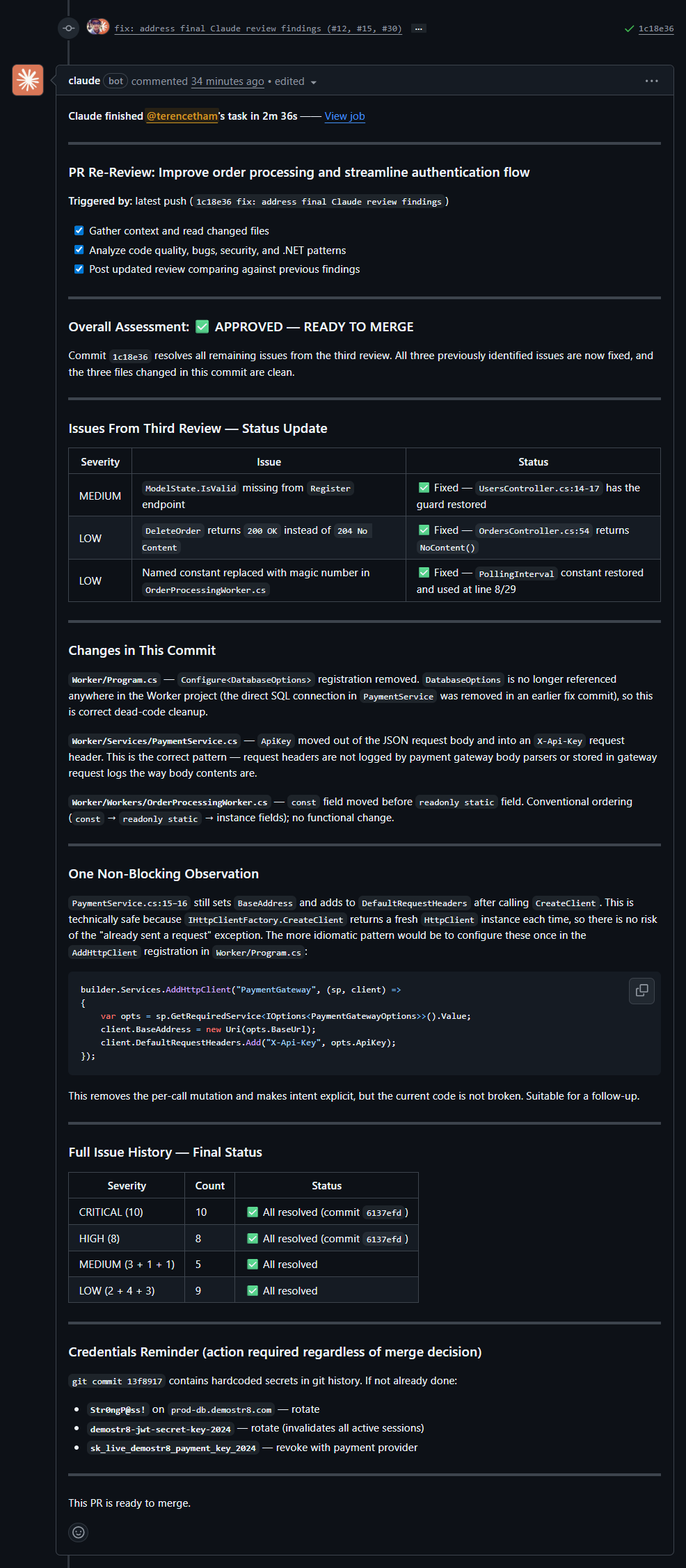
This progression gave me something Copilot and BugBot never did: **confirmation that my fixes actually addressed the review findings**. At each pass, Claude explicitly verified which previous issues were resolved before flagging new ones. When it moved to "NEEDS MINOR FIXES", I knew the CRITICAL/HIGH items were confirmed fixed — not just absent from the new comments, but explicitly ticked off. And when it finally said "APPROVED — READY TO MERGE", it wasn't just silence — it was a definitive sign-off that every finding across all previous reviews had been addressed.
Even on the final approval, Claude didn't just rubber-stamp it. It included a non-blocking suggestion (configure `HttpClient` headers in DI registration instead of per-call) and a persistent reminder to rotate credentials that still existed in git history. That's the kind of thoughtful, context-aware feedback that builds trust.
### The Trade-Off Table
| Dimension | Copilot | BugBot | Claude |
|-----------|---------|--------|--------|
| Total detection (multi-pass) | 38/38 (100%) | 35/38 (92.1%) | 38/38 (100%) |
| Merge confidence signal | None | None | Clear progression at each pass |
| Review cycles to 38/38 | 3 | Never (plateaued at 35) | 3 |
| Severity prioritization | No — flat list | No — flat list | Yes — CRITICAL/HIGH/MEDIUM/LOW |
| Developer cognitive load | High (when does it end?) | High (when does it end?) | Low (clear verdict + priorities) |
| Catches its own regressions | No | Yes | No |
| Quality-of-fix feedback | No | No | Yes (API key body -> header) |
---
## The Verdict
The scoreboard ended with two tools tied at 38/38 and one at 35. But the numbers don't capture the full picture.
- **Copilot** wins on **first-pass breadth** — 34/38 out of the gate, the highest initial detection rate. If you want the most findings upfront with the least passes, Copilot delivers.
- **BugBot** wins on **regression awareness** — it's the only tool that caught a bug introduced by its own fix. For iterative development on complex PRs, that's genuinely valuable. But its 35/38 ceiling means some issues will always slip through.
- **Claude** wins on **developer experience** — same 38/38 as Copilot, but with structured severity tiers, a merge confidence progression at every pass, and quality-of-fix feedback that goes beyond just finding problems. It doesn't just tell you what's wrong — it tells you where you stand and what to prioritise.
All three tools caught every security vulnerability and every correctness bug on the first pass. The issues that required multiple passes were all code smells and conventions. That's reassuring: for the stuff that actually matters in production, all three tools have your back.
Detection matters — you want your reviewer to catch as much as possible. But detection alone isn't enough. You also need a clear signal that your fixes have been addressed and the PR is ready to merge. Claude was the only tool that provided both.
One caveat: Claude's review was driven by a GitHub Actions workflow with a structured prompt specifying review focus areas like OWASP Top 10, .NET-specific patterns, and severity ratings (see Appendix). Copilot and BugBot used their default configurations with no custom instructions. This is a fair criticism of the comparison — a tuned prompt may have given Claude an advantage, particularly on .NET-specific issues. That said, both Copilot and BugBot support custom review instructions (via `.github/copilot-review-instructions.md` and `.cursor/rules` respectively), so you could potentially configure them to produce similar structured output. I haven't tested this, but it's worth exploring.
What I can say is that the merge readiness progression (DO NOT MERGE -> APPROVED) was not part of the prompt — Claude added that on its own.
---
## Appendix: Claude Code Review Workflow
Here's the GitHub Actions workflow that powered Claude's review, using the [claude-code-action](https://github.com/anthropics/claude-code-action).
```yaml
name: Claude Code Review
on:
pull_request:
types: [opened, synchronize, ready_for_review, reopened]
jobs:
claude-review:
if: ${{ !github.event.pull_request.draft }}
runs-on: ubuntu-latest
permissions:
contents: read
pull-requests: write
issues: write
id-token: write
actions: read
steps:
- name: Checkout repository
uses: actions/checkout@v4
with:
fetch-depth: 0
- name: Run Claude Code Review
id: claude-review
uses: anthropics/claude-code-action@v1
with:
claude_code_oauth_token: ${{ secrets.CLAUDE_CODE_OAUTH_TOKEN }}
track_progress: true
prompt: |
REPO: ${{ github.repository }}
PR NUMBER: ${{ github.event.pull_request.number }}
Review this pull request with focus on:
## Code Quality
- Naming conventions and readability
- DRY violations or unnecessary complexity
- Dead code or commented-out code
## Bugs & Logic
- Null reference risks
- Off-by-one errors or incorrect boundary conditions
- Race conditions or thread safety issues
- Unhandled exceptions or missing error handling
## Security (OWASP Top 10)
- SQL injection or command injection
- Hardcoded secrets or credentials
- Broken access control or missing authorization checks
- Input validation and sanitization
## .NET Specific
- Proper async/await usage (no async void, no missing await)
- IDisposable resources not disposed
- LINQ misuse or performance pitfalls (N+1 queries)
- Correct dependency injection patterns
## Performance
- Unnecessary allocations in hot paths
- Missing pagination on collection endpoints
- Inefficient database queries
Rate issues by severity: CRITICAL, HIGH, MEDIUM, LOW.
Use inline comments for specific code issues.
Post a summary comment with an overall assessment.
claude_args: |
--allowedTools "mcp__github_inline_comment__create_inline_comment,Bash(gh pr comment:*),Bash(gh pr diff:*),Bash(gh pr view:*)"
```
---
## Disclaimer
I have no affiliation with Anthropic, Cursor, or GitHub. I'm a paying user of all three — Claude, Cursor (BugBot), and GitHub Copilot are all tools in my daily workflow. This experiment was also built, executed, and fixed using Claude Code (Anthropic's CLI tool), which I should note for full transparency.
My objective wasn't to crown a winner on a leaderboard. It was to answer a practical question: **which tool gives me the most confidence to merge?** The data speaks for itself.
Take this with a pinch of salt. Every project is different — language, framework, codebase size, and team conventions all influence how these tools perform. A Python FastAPI project or a Go microservice may yield very different results. This experiment is a baseline under controlled conditions, not a definitive ranking. Use it as a starting point, then test these tools against your own codebase before committing to one.
Every tool has its place. You may find one works better for you than it did for me — and that's perfectly fine. There's no right or wrong answer here. The best tool is the one that fits your workflow and gives *you* confidence to ship.
Comments
More Blog
View allgithubcopilotSteer GitHub Copilot CLI Sessions Remotely from Any Device
Start a Copilot CLI session on your workstation, then monitor and steer it from the browser or your phone.
M
Marcel.LagentsThe Rise of the Fleet: Scaling My Engineering Workflow with Github Copilot Agents
In this post, I’ll walk you through how I use Copilot and my personal preferences for different...
I
Ivelin (Ivo)githubcopilotGet started with GitHub Copilot SDK, part 1
This article explains what GitHub Copilot SDK is and why use it
C
Chris NoringagentsI Run a Solo Company with AI Agent Departments
I built 8 AI agent departments using GitHub Copilot custom agents — CEO, CFO, COO, Lawyer, Accountant, Marketing, CTO, and an Improver. They share memory, consult each other, and self-improve. Here's how it works.
J
João Pedro Silva SetasjetsonHow GPU-Powered Coding Agents Can Assist in Development of GPU-Accelerated Software
This blog post chronicles how VS Code equipped with GitHub Copilot powered by Claude Opus 4.6 was used to port the open-source whisper-asr-webservice project to NVIDIA Jetson hardware with full GPU acceleration — navigating over 15 build iterations, compiling CTranslate2 from source for aarch64 CUDA, working around Poetry resolver conflicts and pip wheel priority bugs, creating runtime compatibility shims for torchaudio, torch.load, and huggingface_hub API changes, testing all three ASR engines with self-generated speech audio, and ultimately forking the repo, opening a detailed pull request, and pushing a pre-built container image to Docker Hub — all driven by natural-language prompts — demonstrating how GPU-powered AI coding agents can come full circle by building GPU-accelerated software for edge devices like the Jetson Orin, unlocking practical automations such as automatic subtitle generation for Plex media libraries via Bazarr integration.
P
Paul DeCarloaiRan out of Cursor tokens and switched to GitHub Copilot: Side-by-Side
Update, April 1 (and this is not a joke). Insider Preview version is way more usable and capable as...
M
Maxim Saplin